原来SourceForge上也用cronolog
cronolog - phpMan
哈,原来SourceForge上也在用cronolog
cronolog - phpMan
哈,原来SourceForge上也在用cronolog
你完全不必耐心的看完所有内容,这里想说明的无非是以下2点:
1. 滚屏内容抓取:在HyperSnap的Active Window(ctrl+shift+w)抓取模式下只要启用自动滚屏(Auto Scroll)选项,在抓取的时候当前屏幕就会PageDown的一页一页往下翻,一直翻到底后就将多屏幕网页内容抓取成了一个图片。
2. 存成GIF格式:GIF是文件最小而又能比较好还原原有效果的图片格式。存成PNG格式:PNG是仅次于GIF格式最小而又能比较好还原原有效果的图片格式。
最早使用的压力测试工具是apache的ab(apache benchmark),apache ab做重复压力测试不错,但是每次只能测试一个链接,如何测试一组链接(比如从日志中导出的1个小时的日志,做真实压力测试),后来找到了这个:
Siege是一个压力测试和评测工具,设计用于WEB开发这评估应用在压力下的承受能力:可以根据配置对一个WEB站点进行多用户的并发访问,记录每个用户所有请求过程的相应时间,并在一定数量的并发访问下重复进行。
没想到<s> <u>居然是deprecated HTML标记
准备关键词测试时经常需要进行UrlEncode和UrlDecode,以下是2个常用的单行Perl脚本(正则表达式):输入为日志或关键词列表
按此阅读全文 "Oneliner's url encode (urlencode) and url decode (urldecode) in Perl" »
其实css也是将HTML从数据和表现分离的有力工具。石头的CSS Oriented Design:COD非常合我的口味,摒弃TOD(Table Oriented Design)还真不是意见容易的事情,但是一旦实现,系统本身就实现了分工和协作:就能像Winamp一样换皮肤了,从而发挥用户最大的能动性。最直接的例子就是本网站使用的MT系统,所有的STYLE都来自MovableStyle,。
有时候某些目录下的文件需要增加认证,Apache缺省的认证模块都是很完备的,以下就是一个通过.htaccess文件增加用户认证的例子。即使对于虚拟主机用户也可以通过上传一些文件来实现认证控制。
摘自:Fix Your Site With the Right DOCTYPE!: A List Apart
DOCTYPE的常用声明:按照 HTML 4.01 XHTML 1.0 XHTML 1.1 列表如下,错误的DOCTYPE HTML PUBLIC反而会导致页面解析错误。
按此阅读全文 "DOCTYPE! HTML PUBLIC 声明规范: HTML 4.01 / XHTML 1.0 / XHTML 1.1 DTD" »
在一台新机器上的时候经常忘记一些环境和快捷方式,比如:如何让FREEBSD终端上正确显示中文等。按照tcsh和bash分列如下
博客中国基本上将我所有的知识点进行一次完整的体现,包括:服务器前后台规划,日志统计分析,面向搜索引擎的优化设计和站内全文检索系统。
NULL.IDA 扫描者IP地址的统计脚本作者:Kreny 还在日本留学,他说日本人的很喜欢写笔记:系统管理员会把所有软件的安装过程完整记录下来,我觉得这种习惯的确值得我们学习。
利用lynx -dump的和grep awk组合,导出搜索结果链接列表:
lynx -dump 将结果页面和链接分别导出
grep KEYWORD 过滤出包含KEYWORDS的行
grep -v KEYWORD 过滤出不包含KEYWORDS的行
awk '{print $2}' 打印出第2列
动态缓存是CMS的发展方向,而随着数码相机等数字设备的普及,图片服务又是未来网络服务中一项很重要的方面。
在CMS系统的选型中提到过基于JAVA的:ImageJ。最近吕克让推荐给我一个项目:ImageManipulation webapp
是一个基于WEB的图片处理服务:
可以根据指定的参数进行原图的缩放:动态生成缩略图,加入水印等。对于需要动态进行生成缩略图的服务非常有用。
The WIDI Free Software/Open Source Developer Survey
http://widi.berlios.de/paper/study.html
一项针对Free Software/Open Source 开发者的调查,调查内容涉及到这些开发者的地理分布、个人背景等等,可惜太长了只大概浏览了一遍
Developer Locations在对开源领域的贡献这方面,我们输给了日本:(——是因为我们起步比他们晚吗?
吕克让
从我的REFERER统计中认识到的人能学到越来越多的东西:逐渐养成了每天到REFERER到我的网站上来的主页上去溜达一下的习惯。
今天在Isli's网站上看到一个很方便的配色生成工具:slayeroffice | tools | color palette creator v1.4
要是有调色板功能就更好了。
参考:
无障碍网页开发:规范及技术手册
提高Web 设计的可读性 (web design readability)
看到这篇规范收获很多:其中关于radio button的可用性是这样描述的:
Vs第一个表单必须点击radio本身才能做选项切换,第2个表单只需要点击文字部分就能做相应的选项切换。虽然只是一点点改进,但是让用户鼠标可以比较容易的进行模糊的操作。
源代码如下:主要是通过label和相应的id做了关联
<form>
<FIELDSET>
<LEGEND>不好的设计:</LEGEND>
<INPUT name="sex" type="radio"
checked>男性<INPUT type="radio" name="sex">女性 <<--
点击"女性"左边的radio才能做选项切换</FIELDSET>
</form>和<form>
<FIELDSET>
<LEGEND>好的设计:</LEGEND>
<INPUT name="sex" type="radio" id="male"
checked><LABEL for="male">男性</LABEL><INPUT
type="radio" name="sex" id="female"><LABEL for="female">女性</LABEL>
<<-- 点击"女性"这个文本就能够做选项切换</FIELDSET>
</form>
Georgia & Verdana 这2种字体的确是很多BLOG中常见的字体,以至于虚线的边框和Georgia都感觉是blogger的特征。其实很多blog系统的设计都遵循了W3C的CSS2 + XHTML 1.1 规范,通过与内容的分离,使得这些系统的表现更加丰富。
Unix is a Four Letter Word: Vi ---> Search and Replace
VI中:
1,$ s/pattern/newstr/g
用sed更方便:
sed -e s/pattern/newstr/g filename > filename.new
谢谢DelphiJ
1)项目管理的软件
Edgewall | Trac,内置了wiki,还有 Subversion版本控制。是用 Python写的,使用SQLite数据库。大家看看是否适合于wego的开发管理。
2).htaccess的管理
上次zheng提到.htaccess文件的控制,有两个有用的参考:
htAccess Generater Demo
.htaccess utorial - Part 1
ouyang
使用PHP的mail函数做邮件发送的例子:
<?php
mail("nobody@example.com", "the subject", $message,
"From: webmaster@{$_SERVER['SERVER_NAME']}\r\n" .
"Reply-To: webmaster@{$_SERVER['SERVER_NAME']}\r\n" .
"X-Mailer: PHP/" . phpversion());
?>
更详细的邮件头信息说明:
Google的XML接口 XooMLe:XooMLe
* Samples
Swap two item
s/(\S+)\s+(\S+)/$2 $1/
Search C identifier
m/[_A-Za-z][_A-Za-z0-9]*/
m/[_[:alpha:]][_[:alnum:]]*/
Empty Line
/^$/
Word
\b\w+\b
* Questions
* Reference
perlre (bytes and utf8)
regex.h (regcomp regexec regfree regerror) (single byte only)
java (unicode only)
python (bytes and unicode)
今天从Oracle的技术文档上看到了:
AWK:Linux 管理员的智能工具包,回想起自己学习使用awk的过程:都是从打印出日志的某个字段这个需求开始的。
摘自今天的WSJ中文版的今日要闻:
我将链接部分用[]标注了:
的标题的设计很规范:链接部分是所有文章标题的头几个字。感觉想是通过机器自动识别的。
原先在CMS的设计中一直考虑过如何进行文章主题词的自动提取,标题的主语看来是一个非常重要的环节。另外一个因素就是通过词性:主题中心词一直提取到遇到第一个动词或者形容词前。
有了文章中心词:就非常好做文章之间的相关引用了。感觉通过标题主语的方式,还是非常容易通过全文索引将历史归档内容关联起来的。
第一次尝试MagpieRSS,因为没有安装iconv和mbstring,所以失败了,今天在服务器上安装了iconv和mbstring的支持,今天仔细看了一下lilina中的rss_fetch的用法:最重要的是制定RSS的输出格式为'MAGPIE_OUTPUT_ENCODING' = 'UTF-8'
样例代码如下:
<?php
// $Id$
// including
require_once("rss_fetch.inc");
// specify output encoding default is ISO-8859-1
define('MAGPIE_OUTPUT_ENCODING', 'UTF-8');;
define('MAGPIE_FETCH_TIME_OUT', 60 * 180);
$url = $_GET['url'];
$rss = fetch_rss($url);
print_r($rss);
?>
用awk命令计算文件中某一列的总和:
awk 'BEGIN{sum=0}{sum+=$1}END{print sum}' data.txt
比较完整的一个例子:
awk -F ',' 'BEGIN{sum=0 ;count=0}{if ($(NF-11) == 2 && $NF == 0 && $3 == "1.6.1_1_1") {sum +=$5; count++;} } END {print "sum="sum" count="count " avg="sum/count}'
说明:
BEGIN{sum=0 ;count=0} 初始化计数器;
END {print "sum="sum" count="count " avg="sum/count} 打印汇总,计数器 和均值;
if ($(NF-11) == 2 && $NF == 0 && $3 == "1.6.1_1_1") {sum +=$5; count++;} 判断倒数第11个字段,判断倒数第一个字段,判断第三个字段(字符串) 第五个字段汇总累加,计数器累加
是从搜索力排行榜认识TraCQ的:他们的数字还是非常有依据的。
仔细看了他们的服务,发现TRACQ的在线客服是一个很新颖的模式:
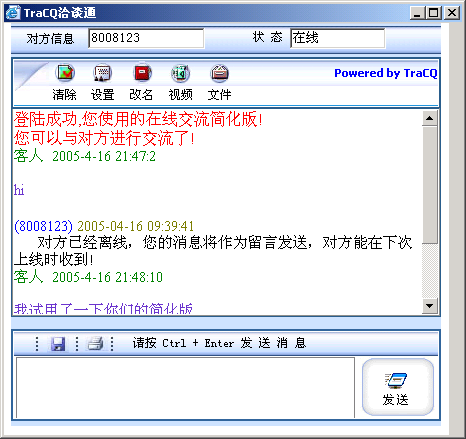
简单的说:TraCQ的在线客服就是网页=>即时通讯工具的服务。这个在线用户反馈入口可以部署在企业网站的每一个网页上,而企业客服人员可以通过即时通讯工具直接对正在浏览网页的客户进行即时在线客户服务。
这可能让很多人想起了最早ICQ的WEB入口工具:你可以通过部署一个简单的JavaScript,你网站的客户就可以从一个在线表单中直接给你的ICQ发送留言。(后来这个功能被大量的spam bot所淹没)
但是在线即时消息的接口的确是有其潜在商业价值的:国外也有提供类似服务,比如:www.chatango.com

假设有一个客户找到了你的网站(比如从搜索引擎),他会如何跟你联系呢?目前传统的手法可能是电话联系,这就需要你在所有网页上都不一定有联系或者定购方式,即使有:如果用户是一个外省的客商,肯能因为长途费用而放弃当前的进一步询问。
对于一般商家来说:申请一个800免费电话服务可能是非常贵的,但如果是一个直接部署在网页上的在线呼叫中心服务就是一个相对成本较低的解决方案。
很多人问过我:你的网站在地址栏中的那个图标是怎么弄出来的?
这个文件就是在WEB根目录下的favicon.ico文件:
http://www.example.com/favicon.ico
很多门户网站都有这个文件。
我觉得它的作用和MSN中的人物头像类似,可以称作“网站头像”吧。
Favicon以前只是在IE收藏时会用到,但现在很多多窗口的浏览器都支持,比如我使用的AvantBrowser:

目前很流行的FireFox:

Favicon可以方便用户在很多窗口的时候快速定位到他需要的那个TAB:人对图像的识别速度还是比抽象的文字还是要快很多。
favicon.ico文件生成还是有些难度的:它不是标准的位图文件,需要用专门的favicon编辑器生成。我很喜欢的一个在线favicon生成器服务:直接上传你喜欢的图片,直接生成16*16像素的favicon.ico文件,还有在线预览功能。
看了Fedora Core 3 Linux on Thinkpad T42这篇文章后,终于明白了为什么Partition Magic会出 Error 117. Partition's drive letter cannot be identified.错误信息:原来是遇到了ext3分区的缘故,我没有精力将原来安装的Debian转成ext2然后再转回来。于是只好将Debian的分区利用Windows的管理工具都删除了在再用PM进行分区。重新启动后,Grub出错,用Windows XP安装盘重新引导一次就好了(不用安装)。
所以:如果在桌面系统上安装Linux学习:最好还是用一些比较经典的文件系统 像ext2,这样万一那天有需要重新划分硬盘分区,可以省缺不少麻烦。
从Moslem那里看到的:Happy Accident ?!:转载如下
如果听过新东方老罗语录,不知是否记得其中的一个“Happy Accident”的片断? 最近一堆事好不容易处理完了,中间偷了点空闲,无聊至极打开 Notepad 玩,无意之中点了一下帮助,发现 Notepad 还有这样一个特性:在文件的头部加上“.LOG”,这样每次打开文件时,焦点都会自动定位到文件结尾,并加注当前日期。有时间可以试试,比较有趣。现在才明白“记事本”(Notepad)是原来是这么个意思。
我尝试了一下:非常方便,立刻就介绍给了其他同事。注意:第一行.LOG一定要大写并顶头开始!(估计NotePad的log模式触发就是通过判断一个文本文件的头4个字节是不是".LOG")
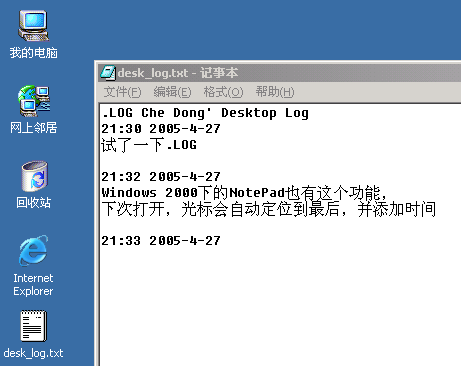
在Windows XP/2000下测试通过。
2001年有关于肯德基的炸薯条断顿的事件报道。从中可以看到一种更高效的管理体系:对于快餐店这样全球性企业来说:要保证各地提供的薯条品质基本一致,成本最低的方法肯定是依靠机器而不是厨师,如果薯条机处理的土豆形状不一,机器的复杂程度和维护成本都会很高。所以土豆必须严格符合工业标准才能让结构比较简单的薯条机生产出符合标准的薯条。RSS和肯德基的土豆标准是一样的,体现了社会分工的细化:简单/可靠的规格意味更低高效的分工和更丰富的应用。
什么是RSS: Real Simple Syndication最能体现RSS的本意
对于应用服务的开发者来说:应用和应用之间,企业和企业之间交换的数据好比就是土豆,白菜,按照严格的XML标准设计的接口的确能大大简化下游开发的后期加工机器成本:可以比较一下处理HTML网页的浏览器,比如:IE和FireFox等软件安装后大小都在10M以上,但一般处理XML的解析器工具包一般都在几百K就够了。这点在未来2,3年,随着移动终端的发展,像手机这样的硬件配置比较低的设备环境中显得尤其重要。
套用生产/代理/零售模式:而将这各个环节高效联系起来的:正是RSS/XML相关标准。
生产商:RSS生产者包括Blog / 新闻网站等;
代理商:RSS聚合服务: FeedBurner/ RSS搜索服务 TechnoRati
零售商:RSS阅读器(RSS Reader/Browser)
从中也可以看到一些MVC(The Model-View-Controller)模式的影子。
下面一些例子:看看RSS如何让互联网变得更加丰富
MovableType/FlickR/del.icio.us是我最常用的3个blog工具:MT用于写一些篇幅稍长的文章,del.icio.us是link blog,用于收藏随时看到的网页资料,FlickR是图片blog,用于看图说话。
而这3个服务恰好都被FeedBurner支持:形成了一个我的个人专辑。
这3个服务都不约而同的提供了方便的JavaScipt快捷键,称之为:bookmarklet。将他们的添加到链接栏上以后,可以将当成一个发布/编辑快捷键使用:可以将当前网页的标题/链接/图片转贴到del.icio.us/mt/flickr上。后2个服务我都是在安装并熟悉使用了bookmarklet后,才开始大量使用的,看来发布的易用性是决定用户使用频度的关键因素。
按此阅读全文 "常用的3个bookmarklet: Mt it + del.icio.us it + FlickR it" »
最近Winter刚教会了我一个文件比较命令: comm,是一个比diff更简单的取2个文件交集/补集的方法。原先以为需要用join 2个表的方法,现在很少几个参数就实现了。
随着时间的积累,我发现原先很多需要用数据库才能实现的排序,过滤,分列输出其实都可以shell代替了:而且效率更高。目前正在整理积累起来的oneliner工具集,经常使用的有:
awk: 可用用作select 控制指定列的输出,并且附带了length() mod 等简单函数,通过if条件还可以实现更复杂的判断逻辑,而且比perl更容易读
sed: 控制到某一行的输出 相当于limit 30,40
perl:正则表达式 过滤,替换,非常强大,网上可以找到很多的one liner的现成工具,不过阅读起来有些困难;
sort: 相当于 order by
uniq: 相当于distinct
grep: 相当于like, not like
wc: 相当于count()
再加上翻页输出more head等。结合报表输出工具:GNUPlot,R-Project等,就可以生成漂亮的报表了。谈不上数据挖掘,但是用于一些简单actionable data采集确实是非常快速有效。
用到的很多小应用中:数据的设计都遵循了加入前缀名的规范。这样可以有效的避免用户在虚拟主机上只有一个数据库限额的时候不同应用之间的表重名问题。
比如:
MovableType是mt_开头,
WordPress是wp_开头
wakka是以wakka_开头,
而且以上这些应用是可以在安装时候使用不同的扩展名的:这样也便于同一个应用的不同版本存放在一个数据库里相互不影响。
最近我的雅虎邮箱(bigfoot邮箱的转发地址)总是收到bigfoot的服务警告:
Dear Bigfoot Member,
We have temporarily suspended your email account chedong@bigfoot.com.
This might be due to either of the following reasons:
1. A recent change in your personal information (i.e. change of address).
2. Submiting invalid information during the initial sign up process.
3. An innability to accurately verify your selected option of subscription due to an internal error within our processors.
See the details to reactivate your Bigfoot account.
Sincerely,The Bigfoot Support Team
+++ Attachment: No Virus (Clean)
+++ Bigfoot Antivirus - www.bigfoot.com
附件是一个zip文件:雅虎邮箱查不出病毒
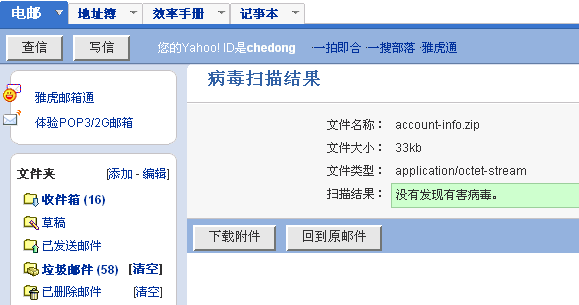
但是下载这个附件一解包:立刻查出了病毒
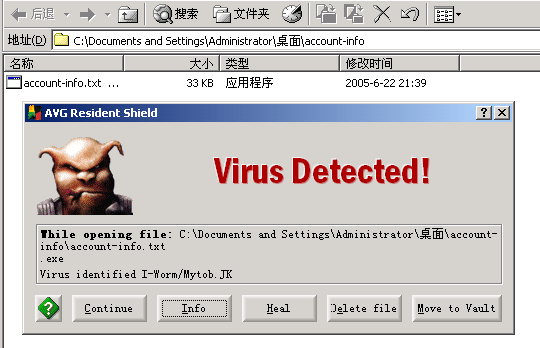
文件名是一个隐藏的.exe文件:中间有大量的空格
“account-info.txt________________________.exe”
spyware真是越来越狡猾了。
订阅Lucene开发邮件列表的朋友已经感觉了一次邮件轰炸:约有700封来自Lucene相关的Bugzilla的相关更新。仔细一看原来是邮件列表的地址由原先的:lucene-dev@jakarta.apache.org 改成了:
java-dev@lucene.apache.org
Lucene在年初(2005-02)成为Apache的顶级项目:luene.apache.org。而做为原先蜘蛛和分布式引擎的Nutch于本月(2005-06)初也做为子项目之一加入Lucene:lucene.apache.org/nutch/ 并列的有原先基于java的Lucene和基于C实现的Lucene这2个项目。
回顾一下Lucene的历史:无一不说明全文搜索服务做为网络基础服务得到越来越多的重视。
卢亮最近忙什么呢?BLOG也很久没更新了。上周的一次小聚才了解到:原来他一直在准备自动类聚技术,利用自动类聚技术改进一些现有BLOG发布系统的关联机制:
1 文章的自动分类:
实现类似于目前news.google.com首页那样的自动主题分类,目前初步规划是将内容分成10个大类,据说目前的精确度已经在95%以上;
2 相关文章功能:
类似于很多门户网站新闻那样的相关新闻,不要小看每篇新闻中那后面几篇相关新闻:在没有全文索引机制之前,像新闻这样的发布系统管理的文章之间的关联是很少的(孤岛),所以每篇新闻的生命周期只有短短的2天(从首页上下去以后,除了用户主动搜索就很少有被再次访问到的机会了)。BLOG也是类似的问题,要知道:用户的注意力是稀缺资源,只有少数的BLOGGER的内容能得到足够的注意力/反馈,很多人开始BLOG后,都是由于无法得到足够的反馈而放弃了。BlogChina上每天上万的发布量,但是真正能被其他人看到的却是非常少的。而相关文章:无疑是一种增加内容之间相互联系/反馈很有效的机制。
更让我佩服的是卢亮的太太:明珠,她是目前这些应用的主要实现者。
tag.bokee.com是第一步,让用户自己定义TAG作为关键词,如果用户没有输入TAG,则利用自动主题提取机制将内容类聚在一起。这部分的应用在BlogChina每篇文章后面的“手拉手”模块中。而再下一步:可能就是类似于AdSense那样的上下文广告关联了吧,将所有的浏览行为都变成了一次隐含的搜索。
根据我目前观察:TAG仍然是质量非常高的主题提取机制,毕竟经过人工编辑的文章主题还是非常明确的。
Hornbill Literary Essay:在十九世纪三十年代的欧洲大陆,一种方便,价廉的圆珠笔开始在书记员,银行职员甚至是富商中流行起来。制笔工厂开始大量的生产圆珠笔。不久却发现圆珠笔市场严重萎缩。原因是圆珠笔前端的钢珠在长时间的书写后,因摩擦而变小继而脱落导致笔筒内的油泄露出来。弄的满纸油啧,给书写工作带来了极大的不便。人们开始厌烦圆珠笔,从而不在用它了。
一些科学家和工厂的设计师们开始为了改变“笔筒漏油”这种状况进行了大量的工作。其中一个科学家做了大量的实验。他实验了上千种不同的材料来做笔 前端的哪个“圆珠”,以求找到寿命最长的“圆珠”。但结果却不很理想。 这时一个叫马塞尔 比希的人却很好的将圆珠笔做了改善,解决了“漏油”的问 题。他的成功是得益于他的一个想法。“既然不能将圆珠笔的寿命很好的延长,那为什么不主动的控制圆珠笔的寿命呢?他所做的工作只是在实验中找到一颗“钢珠”所能完成书写的“最大用油量”。然后每支笔所装的”“油”都不超过这个“最大用油量”。 这样,方便,价廉又“卫生”的圆珠笔有成了人们最喜爱的书写工具之一。
前2天看到:Google与李开复博士: 大学生如何为加盟Google做准备
中间有一条:(2)多实战。通过编程的实战积累经验、内化知识。建议大家争取在大学四年中积累编写十万行代码的经验。
这点我非常有赞同,但对于大部分学生来说没有方向是一个主要问题。去哪里找项目做呢?我推荐:SourceForge.net:那里有大量的开源项目,虽然项目的质量良莠不齐,其中有不少项目是半成品,这里也是很多国外在校学生毕业设计的试验田。先找一两个自己能用的系统:比如BLOG TWIKI。搭建起来使用一下,使用过程中遇到的问题想办法自己从代码层面解决,然后将修正提交给相应项目争取加入到下一个发布版本中。从中应该很快能学到不少东西,包括如何参与多人项目的合作开发等等……
前2天读到了? RSS阅读中潜在的安全问题 | 未完成 - Incomplete,讲的是混杂在Rich Text的RSS中的js会在RSS阅读客户端执行从而导致潜在的漏洞问题。正巧我在上个周末的时候也遇到了类似的一个问题:不过更严重的是在RSS聚合的服务器端。
我的首页是用require_once('lilina.html') 的方式包含一个lilina.php生成的静态页面组合生成的,源代码如下。其中也包含了跨服务器PHP脚本执行的安全漏洞。如果我订阅的RSS中有黑客将其中混入 <?php >这样的代码,这样一包含:不就可以直接在我的服务器上直接运行php脚本了吗?这个潜在漏洞的发现还是从MSN的Search blog的一篇FEED中引出的。
将自己的留言簿迁移到groups-beta.google.com后,刚开始发现清静了很多,但不久以后就发现比原来更加严重的comment spam 比MT的留言簿更是有过之而无不及:

不得不将Google Groups中的很多留言模式设置成了需要批准才能发布,回复的时候也很不方便,自己的回复还需要自己批准一下……
今天查MagpieRSS的资料的时候看到了这个BLOGThe Fishbowl: 他的座右铭: tail -f /dev/mind > blog 让我一下子想起了Jeremy Zawodny's blog
SELECT * FROM random_thoughts ORDER BY date DESC
谢谢HeRock的帮助,重要等到了Zoundry的邀请。
以下是工作界面截图:
这个工具对于Web开发者来说真是太方便了:LinkChecker - Firefox link validator extension for web developers
安装上插件后,右键一点就开始对当前页进行检查了:在自己的首页上试了一下
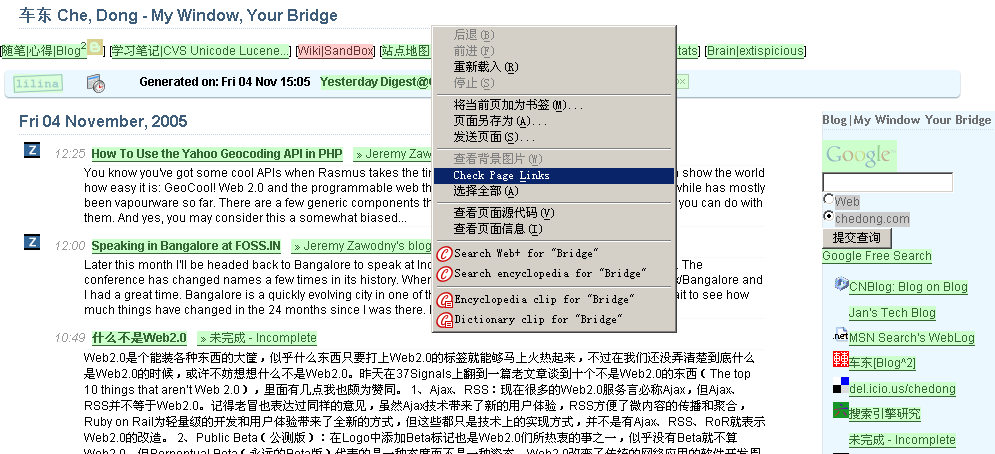
绿色:Good
红色:死链
黄色:转向/禁止访问
灰色:忽略链接,锚链或者邮件地址等
感谢RainX的推荐。
按此阅读全文 "FireFox死链检查插件:LinkChecker - Firefox link validator extension for web developers" »
曾经介绍过给自己的Blog加上Y!Q用于在互联网上搜索搜索相关文章http://www.chedong.com/blog/archives/000910.html,但目前Y!Q对于中文的支持有限,而且实时性很差。我暂时从模板中去掉了。其实猫叔介绍过另外一个将MT内部文章通过关键词(Tagging)相互串连起来的机制。那个插件叫做MTRelatedEntries ByKeyword。原理就是利用MT的关键词字段,设置多个tagging,从而达到文章之间多对多的分类组合。
1 打开关键词编辑,MT的文章编辑界面中,缺省是不包括关键词字段显示的:需要自己“定制此窗口的显示方式”
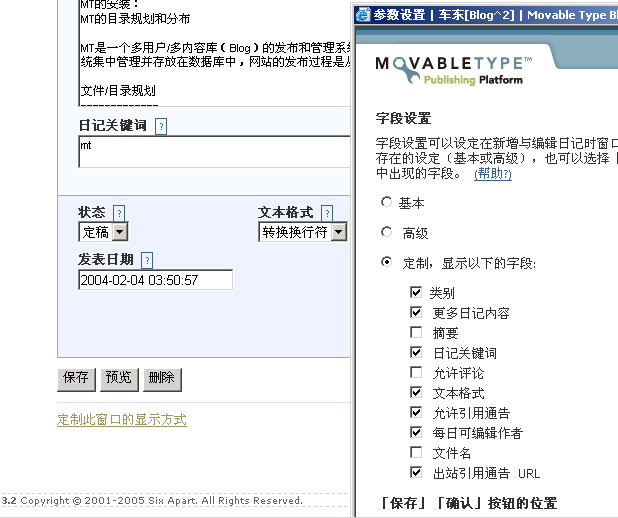
3 在模板中加入:
<MTEntries lastn="6">
<$MTEntryTitle$>
<ul>
<MTRelatedEntriesByKeyword>
<MTEntries lastn="5">
<li><$MTEntryTitle$></li>
</MTEntries>
</MTRelatedEntriesByKeyword>
</ul>
</MTEntries>
以后每次发表文章的时候加上自定义的关键词(可以是多个),就实现了MT文章内部之间基于tagging的类聚。
使用StatViz跟踪“用户”点击中,唯一用户缺省是根据同一个IP定义的,就是假设来自同一个IP的为同一个用户,这样定义对于访问量较低的站点可能这样定义没有问题,但是对于访问量较大的站点,来自同一个IP后面有多个用户(比如代理服务器)就不一样了。而同一个用户在不同的时间可能使用不同的IP地址在线。对于这样的情况,要长期跟踪用户行为:使用一个长期有效的Cookie进行用户跟踪是一个比较简便途径。
Apache本身带有一个mod_usertrack模块:其原理就是在用户首次来到当前网站的时候给用户种下一个唯一的cookie(较长时间过期),这个cookie是用户首次来当前网站的IP地址加上一个随机字符串组成的。
1.2.3.4 ... 1.2.3.4.1111 用户1
1.2.3.4 ... 1.2.3.4.2222 用户2
1.2.3.4 ... 1.2.3.4.3333 用户3
第2天,即使用户换了IP,
1.2.1.2 ... 1.2.3.4.1111 用户1
具体的配置方法如下:
1 启用mod_usertrack模块:
LoadModule usertrack_module libexec/mod_usertrack.so
AddModule mod_usertrack.c
2 针对一个域名启用CookieTracking
CookieTracking on
CookieDomain .chedong.com
CookieExpires "10 years"
CookieStyle Cookie
3 mod_usertrack的记录: 在日志最后增加%{cookie}n字段
LogFormat "%h %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\" %{cookie}n" combined
启用mod_usertrack后的日志样例:
202.160.180.61 - - [30/Nov/2005:17:38:44 +0800] "GET /phpMan.php/man/HTML::AsSubs/3pm HTTP/1.0" 200 4911 "-" "Mozilla/5.0 (compatible; Yahoo! Slurp China; http://misc.yahoo.com.cn/help.html)" 202.160.180.61.227021133343524377
218.249.22.70 - - [30/Nov/2005:17:38:45 +0800] "GET /referer.js HTTP/1.0" 200 26254 "http://bietile.bokee.com/" "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0)" 218.249.22.70.11531133343525235
202.160.180.61 - - [30/Nov/2005:17:38:48 +0800] "GET /phpMan.php/man/File::CheckTree/3pm HTTP/1.0" 200 4654 "-" "Mozilla/5.0 (compatible; Yahoo! Slurp China; http://misc.yahoo.com.cn/help.html)" 202.160.180.61.222451133343528428
然后在StatViz中设置改用最后一个Cookie字段作为唯一用户的跟踪,这样的独立用户会话统计就更准确了:
; Column 0 is the first column -- by default this is the "combined" apache log format, but of course you can customize
LogSessIDColumn=10
...
昨天看到AWStats的一些扩展统计:ExtraSection真实太有用啦,原先需要grep "index\.xml|index\.rdf|atom\.xml" access_log|awk -F '"' '{print $4}' |sort|uniq -c|sort -rn|head -30 这样的统计用以下配置就可以实现啦,而且有漂亮的表格输出。
ExtraSectionName3="Top RSS Reader/Spider"
ExtraSectionCodeFilter3="200 304"
ExtraSectionCondition3="URL,index\.xml|index\.rdf|atom\.xml"
ExtraSectionFirstColumnTitle3="RSS Reader/Spider"
ExtraSectionFirstColumnValues3="UA,(.*)"
ExtraSectionStatTypes3=HBL
MaxNbOfExtra3=30
MinHitExtra3=1
WordPress已经是非常流行的blog发布系统了,但缺省的blog发布是不支持PermaLink的(可能是考虑到在Windows平台和Apache 2.0上缺省不支持PathInfo)。
将上次从MT迁移到WP的笔记补充一下关于PermaLink的设置:
在WordPress中设置PermaLink的方法:
选项(Option)==>永久链接(Parmalink)设置中:位于 /wp-admin/options-permalink.php
文章详情页结构: /%year%%monthnum%/%day%_%post_id%.html
注意:如果是中文名称的目录,经过UrlEncode编码后的地址无法映射回原来的目录名。
例如:
http://blog.example.com/category/%e9%85%b7%e8%ae%af%e4%ba%a7%e5%93%81/
因此还需要编辑一下每个目录的Slug(分类缩略名)属性:管理==>类别==>编辑类别中,将每个目录设置一个"分类缩略名"。然后类目的输出就会按照英文的分类缩略名进行输出了,例如:
http://blog.example.com/index.php/archives/category/games/
文章页输出样例:
http://www.adayang.com/index.php/2007_01_16_103.html
目录列表页输出样例:
http://www.adayang.com/index.php/category/daily-life
phpMan.php是一个unix上将man page展现在web界面上的php脚本工具,虽然做了一定的防命令行漏洞处理,但是上周还是被LoaA发现了有XSS安全漏洞:
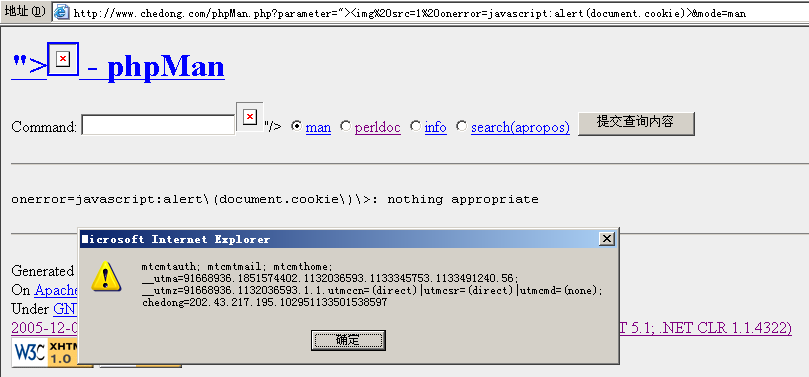
所谓XSS:就是Cross Site Script 跨网站脚本漏洞的缩写。如果纵容这种漏洞有什么危害呢?
上图只是破坏者利用脚本打印除了自己在网站的所有的Cookie列表:我们看到的有mt的后台,有analytics的session,还有最近试验的使用mod_usertrack生成的用户识别cookie。如果这个链接是侵入者诱导其他用户在一个第3方的网站上触发,然后引导用户指向当前网站,然后再利用其他的脚本将用户在当前网站的cookie或其他信息发送到另外一个网站上。流程大致如下:
dirty-web.com/spam email ==user click==> commecial-site.com ==send cookie==> dirty-web.com
这样就完成了一次对用户在一个商业网站上的信息盗取。
perldoc -f 用于搜perl内置的函数
perldoc -q 用于在perldoc中进行标题的全文检索
前2天在桑林志上看到DreamHost的主机租用方式:桑林志 CPU usage limit 原来是基于每个客户占用的主机CPU的时间:每个虚拟主机客户每天不能超过40分钟。这让我立刻联想到了Sun的CPU 1$/小时的租用服务:
02/01/05 - Sun Lights Up the Sun Grid First Global Compute and Storage Grid for $1/cpu-hr and $1/GB-mo,在目前的硬件和网络环境的发展下:每客户的硬件成本已经可以比较清晰换算了。真正验证了Sun:网络就是计算机的理念。
其实很多在线服务都不能忽视的在线存储技术/CPU/宽带技术硬件技术的发展:也要看到这些新兴服务在控制成本上的努力。搜索和邮件服务应该是非常好的例子。操作系统和开发语言就不用说了:几乎没有用Windows/Solaris等商业操作系统和开发平台的,基于开源软件的非常普遍。而很多在成本上的严格控制是这些服务能够低成本生存/不至于中途夭折的主要原因:
比如:
FlickR:除了用户的易用性上外,我倒是觉得FlickR的免费用户带宽限制技术倒是很重要的因素,否则好好的一个SocialNetworks服务很容易成为色情图片的宿主? 而del.icio.us也非常有效的控制了link spam;
之前我还做过一个BlogLines的成本分析:缓存机制应该是FeedBurner等这些RSS服务的核心。
flymeteor@Blog � Sed 与 Linux 等价命令代码鉴赏
basename sed 's/\(.*\)\/\([^/]*\)/\2/' or sed 's,.*/,,'
cat sed '' or sed -n '1,$p' or sed '1,$!d'
cat -s sed '/./,/^$/!d'
cat -n sed '=' | sed 'N;s/\n/\t/;s/^/ &/' or sed '=' | sed '$!N;s/\n/ /'
cat -E sed 's/$/\$/'
cat -t sed 's/\t/^I/g'
cut -c n sed 's/\(.\)\{n\}.*/\1/' or sed 's/^.\{(n-1)\}//g;s/\(.\)\(.*\)/\1/g'
cut -c x-y sed 's/\(^.\{y\}\)\(.*\)/\1/g;s/^.\{(x-1)\}//'
cut -d| -f6 sed 's/\(\([^|]*\)\|\)\{6\}.*/\2/'
cp file1 file2 sed 'w file2' file1
expand -t 1 sed 's/\t/ /g'
dirname sed 's/\(.*\)\/\([^/]*\)/\1/' or sed 's,[^/]*$,,'
grep patten sed -n '/patten/p' or sed '/patten/!d'
grep -v patten sed -n '/patten/!p' or sed '/pateen/d'
grep -n patten sed -n '/patten/{=;p}'| sed 'N;s/\n/:/'
head sed -n '1,10p'
head -1 sed -n '1p' or sed 'q'
head -Number sed '1,Number!d' or sed 'Numberq'
paste -s file1 file2 sed ':a;N;s/\n/\t/;ba;' file1 file2 | sed 's/\t\t/\n/'
paste -sdstr sed ':a;N;s/\n/str/;ba'
rev sed '/\n/!G;s/\(.\)\(.*\n\)/&\2\1/;//D;s/.//'
tac sed -n '1! G;$p;h' or sed -n 'G;$p;h'
tail -1 sed -n '$p' or sed '$!d'
tail -Number sed ':t;$q;N;(Number 1),$D;bt'
tail -f sed -u '/./!d'
tr "\n" " " sed ':a;N;s/\n/ /;ba'
tr "A-Z" "a-z" sed 'y/abcdefghijklmnopqrstuvwxyz/ABCDEFGHIJKLMNOPQRSTUVWXYZ/'
tr "a-z" "A-Z" sed 'y/ABCDEFGHIJKLMNOPQRSTUVWXYZ/abcdefghijklmnopqrstuvwxyz/'
tr -d "12" sed ':a;N;s/\n//;ba' or sed ':a;N;s/\(^.\)*\n\(.*\)/\2\1/;ba'
tr -s 'x' sed 's/\(x\)\(x\{1,\}\)/\1/'
tr -s ' ' sed 's/ \ / /g'
uniq -u sed '$b;N;/^\(.*\)\n\1$/ ! {P;D};:c;$d;s/.*\n//;N;/^\(.*\)\n\1$/{bc};D'
uniq sed 'N;/^\(.*\)\n\1$/!P;D'
wc -l sed -n '$='
wc -c sed ':a;s/./&\n/;P;D;/.\{2,\}\n/ba' t|sed -n '$='
wc -w sed 's/ /\n/g' | sed -n '$='
xargs sed ':a;N;s/\n/ /;ba' or sed -e ':a' -e '$!N;s/\n/ /;ta'
最近每天都看DBANotes: 知道了这个工具
Firefox Installed Extensions - ListZilla
安装后我也列了一下常用的插件:
Generated Wed Dec 28 2005 17:16:22 GMT+0800 Enabled Extensions:
Google Toolbar for Firefox 1.0.20051122 Google工具栏:IE上也有
del.icio.us1.0.2 链接收藏 常用,打开新窗口,从原网页上很方便复制/粘贴
LinkChecker 0.4.5 死链检查工具
View Cookies 1.5 查看cookie工具,最近常用
Live HTTP Headers 0.11 http header查看器
Pearl Crescent Page Saver 0.9.3 浏览器屏幕截图工具
ListZilla 0.7 以上列表就是ListZilla生成的
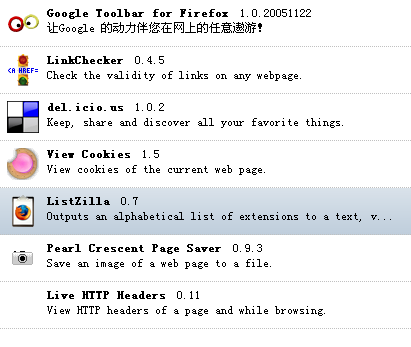 Clusty Toolbar 1.0.6 不常用
Clusty Toolbar 1.0.6 不常用
Performancing 1.0.1 类似于Zoundry的离线blog编写工具 不常用
TWiki Firefox Extension 2.0.3 TWiki格式化工具栏 编写内部文档常用,新版twiki上的可视化编辑器完全可以替代这个插件,而且这个版本在Firefox 1.5.0.1后有不兼容的问题。
对于很多分布式的大流量产品(比如:计数器)来说,随着服务器的分布,日志的集中管理就变得有些麻烦:比如前端多台Web Server的日志统计,传统的解决方法是定期(每小时,每天)截断日志,然后通过FTP 传到一台服务器上进行统一处理,在有些日志的计算处理前,还需要考虑日志的排序问题。
[App Server] [App Server] [App Server] [App Server]
\ | | /
via FTP / SCP daily cron
| |
[Logging Server] (sort merge)
/ \
[other stats] [other stats]

[App Server] [App Server] [App Server] [App Server]
\ | | /
via UDP or Broadcasting
| | |
[Logging Server(syslogd)] <=backup=> [Logging Server(udplogd)] [Real time monitor]
Using AJAX to Improve the Bandwidth Performance of Web Applications这篇文章十分量化的说明了AJAX技术如何节省应用的带宽。我将文章中的2次测试的效果截图用画图组合对比了一下:这样看效果更明显一些
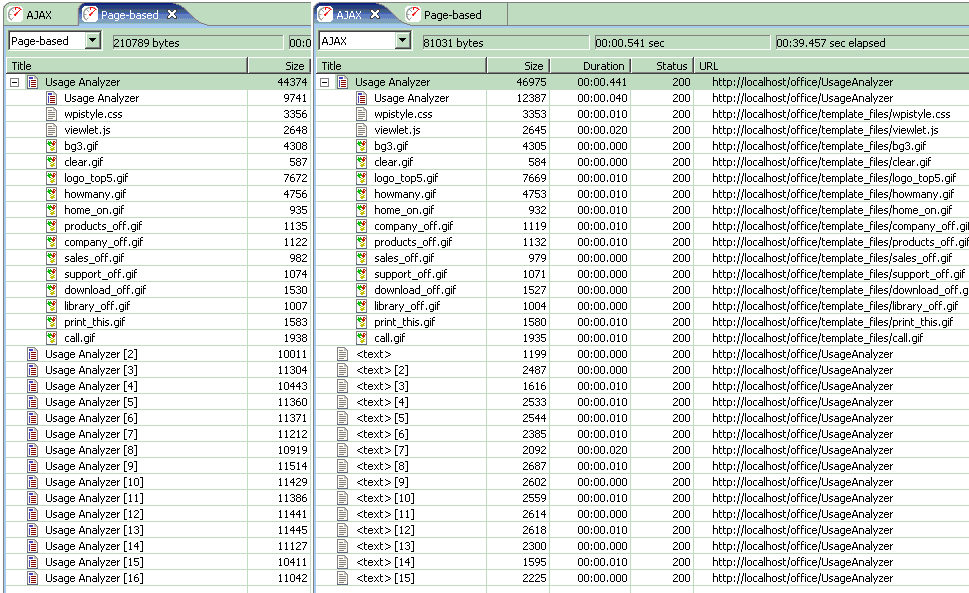
这里有几个基本的结果:
1 包含ajax的应用首次下载要比一般页面刷新方式的应用大:Usage Analyser的ajax版大小12387,原大小9741字节
2 AJAX应用在后面的交互中:只刷新部分需要更新数据 2-3k 而传统的整页刷新模式需要整页重载: 10k左右
3 交互次数越多,AJAX应用的带宽节省效果越明显;
4 整页刷新模式虽然需要重新载入图片等:但由于通知了客户端使用本地缓存的图片和JS等:因此没有重新产生流量,
在此次条件的试验过程中:ajax技术总计节省了超过61%。远远超过预期的50% 而且随着交互次数增加,节省率还会更高。
twiki在DakarRelease中加强了本地化的支持,可以给TWiki设置不同的本地语言界面,这个设置是通过locale/目录下的.po文件实现的,.po是GNU gettext项目的一套应用规范。是一种比较规范的l10n方案。'.po'是: Portable Object(可跨平台对象)的缩写,而创建/编辑.po文件过程中会生成相应的机器码binary的格式文件:'.mo' MO是Machine Object。
元旦放假时翻译是用Notepad对着德文版的翻译一行一行翻译的。几个星期过去了,2月1日TWiki 4.0(DakarRelease)就要发布了,目前的状态是:
Our current status is this:
locale/da.po: 628 translated messages.
locale/de.po: 628 translated messages.
locale/es.po: 270 translated messages, 58 fuzzy translations, 300 untranslated messages.
locale/fr.po: 542 translated messages, 58 fuzzy translations, 28 untranslated messages.
locale/nl.po: 626 translated messages, 2 untranslated messages.
locale/pt.po: 628 translated messages.
locale/zh-cn.po: 548 translated messages, 72 fuzzy translations, 8 untranslated messages.
locale/zh-tw.po: 548 translated messages, 72 fuzzy translations, 8 untranslated messages.Instructions for posting patch against translations are available at:
http://twiki.org/cgi-bin/view/Codev/DakarReleaseTranslations
由于中间开发过程中又有一些文字的修改,这时候再用Notepad编辑,中间已经有些内容很难定位和识别状态了。以前知道Linux平台下有2个分别在KDE和gnome平台下的PO编辑器:GTranslator和KBabel,我尝试了找了一下,发现了另外一个可以运行在Windows下面的.po编辑器:poEdit,使用界面如图
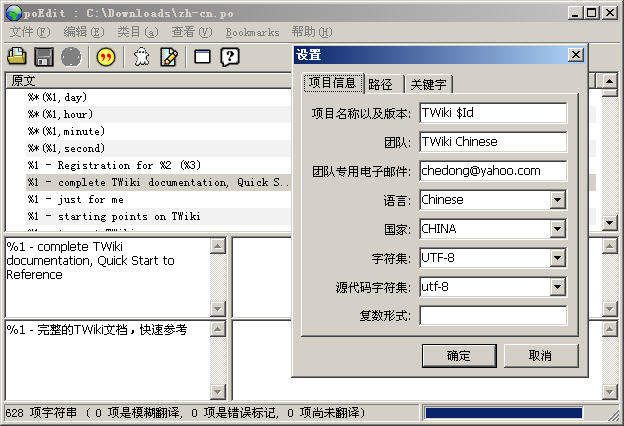
有了gettext系列工具的支持:翻译后的.po还可以通过工具进行校验
msgfmt --statistics --output=/dev/null zh-cn.po
上周末和老肖聚会,见到了BugFree的作者刘振飞。BugFree是国内很成功的一套开源Bug跟踪系统;基于PHP/MySQL架构。下午聊的内容很多也是关于网站和软件开发过程一些流程系统。振飞在微软工作过一段时间:而微软内部的Bug Tracking系统Product Studio是他认为最强大的工具之一。BugFree的很多设计如果是借鉴了Product Studio,那么开发者也能从中感受一下微软成功的开发过程。
我个人对开源软件的开发了解多一点。至少在Apache基金会上可以看到他们使用的是以下几个系统的组合:
版本控制:
最早使用的是CVS,目前已经迁移到了SVN上。
Bug/Issue Tracking:
(可选)JIRA(Java)或者BugZilla
文档共享:
Apache目前选择的WIKI平台是:MoinMoin(Python)
邮件列表/归档:
记得以前用的是EyeBrowse(Java)
TWiki本身非常适合公司内部做文档平台,而twiki这套平台本身开发的过程中,我们也可以看到twiki开发团队的高效的开发过程:
EdinburghReleaseMeeting2006x02x06 < Codev < TWiki
会议模板如下:
http://twiki.org/cgi-bin/view/Codev/EdinburghReleaseMeetingTemplate
* Logistics, Participants, IRC log 参加者
* Agenda 会议议题
* Miscellaneous 其他
* Action Items 行动方案
* IRC Log 谈话纪要
* Comments / Feedback 反馈
习惯了FreeBSD和RedHat上使用/etc/rc.local 定制服务的自动启动,最近用Debian还真有些不习惯。以下是我搜集到的资料:在debian上创建rc.local文件。
创建文件:
sudo touch /etc/init.d/rc.local
设置可执行:
sudo chmod +x /etc/init.d/rc.local
用update-rc.d设置启动级别:
sudo update-rc.d rc.local start 20 2 3 4 5 . stop 20 0 1 6 .
为了编辑方便,创建一个链接:
sudo ln -s /etc/init.d/rc.local /etc/rc.local
cat /etc/rc.local
# start apache
/home/apache/bin/apachectl start
重启一下,没有问题。
后记:Debian 下没有 rc.local ,不过有一个替代品,就是 /etc/init.d/bootmisc.sh 文件(可以将/etc/rc.local 链接过去)
大家有什么需要启动后运行的,尽管往里面塞 :-P
类似的:也是使用update-rc.d 将相应服务设置成启动就可以了。

- web - ?Forum=1 - ?post=1
|- ?post=2
|- ?post=5
- ?Forum=2 - ?post=4
|- ?post=22
|- ?post=8
- index - post10.html
|- post9.html
|- monthly_archive - post8.html
|- post7.html
|- category_archive - post8.html
|- post2.html
由于个人内容发布量较少,在百级或者千级,蜘蛛经过3层遍历基本上能够遍历完整个网站。而blog之间的相互引用非常丰富。邮件列表归档和blog的发布结构非常像:邮件列表归档也有按时间归档的机制,并且使用permalink,
|- topic1 -> topic2
-> topic3
|- topic2 -> topic3
|- topic3 -> topic2
-> topic1
rss.xml - post10.html
|- post9.html
|- post8.html
什么是Tag:上次尝试安装Wikipedia的镜像的时候,了解到了eAccelerator已经是很常用的PHP平台预编译加速的手段了。今天在自己机器上尝试安装了一下,备忘如下:
获得源代码:
http://bart.eaccelerator.net/source/
编译:需要有autoconf支持,解包后在源程序目录下:
/usr/local/bin/phpize
./configure --enable-eaccelerator=shared --with-php-config=/usr/local/bin/php-config
make
sudo make install
extension_dir = "/usr/local/lib/php/extensions"
extension="/no-debug-non-zts-20060613/eaccelerator.so"
eaccelerator.shm_size="16"
eaccelerator.cache_dir="/tmp/eaccelerator"
eaccelerator.enable="1"
eaccelerator.optimizer="1"
eaccelerator.check_mtime="1"
eaccelerator.debug="0"
eaccelerator.filter=""
eaccelerator.shm_max="0"
eaccelerator.shm_ttl="0"
eaccelerator.shm_prune_period="0"
eaccelerator.shm_only="0"
eaccelerator.compress="1"
eaccelerator.compress_level="9"
2006-06-03更新
在apache 2.2的升级过程中:发现php的相关模块都需要重新编译 需要注意包含哪个目录下的 eaccelerator.so 文件
/usr/local/lib/php/extensions$ ls -1
no-debug-non-zts-20020429
no-debug-zts-20020429
否则eAccelerator会无法生效, 我测试的结果在apache 2.2下eAccelerator的效果比apache 1.3下还差一些;
最好创建专用的缓存目录:
sudo mkdir /tmp/eaccelerator
sudo chmod 0777 /tmp/eaccelerator
用phpinfo这个脚本本身还做了一下性能对比测试:对于纯php代码(不考虑数据库瓶颈/文件IO等操作)的运行效率的确有3-5倍的效率提升;
MT做为最成功的blog发布系统之一被spammer叮上有好几年了,虽然在mt 3.2以后垃圾评论的管理已经加强很多,但spammer对于mt的spamlookup的适应速度也是非常快的。昨天做了几个脚本统计,分析了一下垃圾评论中的关键词特征:数据源来自最近十天收到的2000多篇垃圾评论,目前收到的mt spam以英文为主。
30207 http 是的,获得反向链接是spammer最主要的目的:在PageRank做为
22256 biz .biz域名最近是不是降价了?这是spammer使用的主要域名后缀
22181 resea
21318 gay
10600 href spam中一般包含大量的html标签,后面还有 _blank target等;
5018 com
4974 boy
3134 info
3075 teen
2426 adobe 除了色情类的关键词,国外还有经常推销打折软件,这在中国是很难想像的,
2393 porn
2373 acrobat
2282 nude
2281 video
2267 sex
2082 url
1821 male
1653 html
1575 movie
1547 guys
1534 www
1529 strong
1297 pic
1291 cock
1278 pro
1270 man
1124 twinks
1054 anal
983 xxx
977 young
941 hardcore
880 picture
812 black
775 best
764 regards
744 buy
733 hot
732 fucking
728 blog
726 target
726 _blank
723 gallery
716 the
704 russian
696 lide
680 online
677 viagra
639 ultram
632 150m
623 weight
615 valium
609 blogspot blogspot是spammer经常使用的免费hosting之一。
588 cum
584 free
570 naked
562 kissing
559 sexo
556 free6xxx
545 ass
544 phentermine
528 rapidforum
528 64751
501 mujweb
490 and
489 cute
464 valiumonline
442 yahoo yahoo邮箱是spammer常用的fake邮箱地址;
436 cheap
428 lose
401 net
380 xxxcredo
376 freesexcredo
366 myteeundercar
360 freexxxcredo
341 site
336 pornzzz
328 you
321 found
306 dan
304 page
304 org
296 post
292 see
292 fuck
292 credosex
289 college
288 clip
288 adult
286 little
285 model
277 gratis
267 praize
259 discount
258 big
236 nice
232 fat
224 three
224 amateur
223 fc2
219 with
由于缺乏模板系统,以前使用html编写的笔记已经很久没有更新了,如果需要对页面内容进行一些更新(比如要更换一下页面中的CSS文件路径),可以用sed完成。对于多个文件的批量处理,整理步骤如下:
1 先创建一个temp目录,将需要更新的文件放到这个临时目录工作下:
cp *.html temp/
2 用ll + awk组合生成脚本文件:
ls -1 * | awk '{print "sed s#/style.css#/blog/styles_zh-cn.css#g "$1" > ../"$1}' > sed.sh
生成后的脚本文件如下:
sed s#/style.css#/blog/styles_zh-cn.css#g acdsee.html > ../acdsee.html
sed s#/style.css#/blog/styles_zh-cn.css#g ant.html > ../ant.html
sed s#/style.css#/blog/styles_zh-cn.css#g apache_install.html > ../apache_install.html
sed s#/style.css#/blog/styles_zh-cn.css#g awstats.html > ../awstats.html
sed s#/style.css#/blog/styles_zh-cn.css#g cache.html > ../cache.html
sed s#/style.css#/blog/styles_zh-cn.css#g click.html > ../click.html
sed s#/style.css#/blog/styles_zh-cn.css#g cms.html > ../cms.html
sed s#/style.css#/blog/styles_zh-cn.css#g comment.html > ../comment.html
sed s#/style.css#/blog/styles_zh-cn.css#g compress.html > ../compress.html
sed s#/style.css#/blog/styles_zh-cn.css#g cvs_card.html > ../cvs_card.html
sed s#/style.css#/blog/styles_zh-cn.css#g default.html > ../default.html
sed s#/style.css#/blog/styles_zh-cn.css#g dev.html > ../dev.html
sed s#/style.css#/blog/styles_zh-cn.css#g gnu.html > ../gnu.html
sed s#/style.css#/blog/styles_zh-cn.css#g google_ads.html > ../google_ads.html
sed s#/style.css#/blog/styles_zh-cn.css#g google.html > ../google.html
sed s#/style.css#/blog/styles_zh-cn.css#g google_url.html > ../google_url.html
sed s#/style.css#/blog/styles_zh-cn.css#g hello_unicode.html > ../hello_unicode.html
sed s#/style.css#/blog/styles_zh-cn.css#g indent_tools.html > ../indent_tools.html
sed s#/style.css#/blog/styles_zh-cn.css#g index.html > ../index.html
sed s#/style.css#/blog/styles_zh-cn.css#g link_pop_check.html > ../link_pop_check.html
sed s#/style.css#/blog/styles_zh-cn.css#g lucene.html > ../lucene.html
sed s#/style.css#/blog/styles_zh-cn.css#g mysql.html > ../mysql.html
sed s#/style.css#/blog/styles_zh-cn.css#g nat.html > ../nat.html
sed s#/style.css#/blog/styles_zh-cn.css#g oe2html.html > ../oe2html.html
sed s#/style.css#/blog/styles_zh-cn.css#g oracle.html > ../oracle.html
sed s#/style.css#/blog/styles_zh-cn.css#g resin.html > ../resin.html
sed s#/style.css#/blog/styles_zh-cn.css#g rotate_merge_log.html > ../rotate_merge_log.html
sed s#/style.css#/blog/styles_zh-cn.css#g sed.sh > ../sed.sh
sed s#/style.css#/blog/styles_zh-cn.css#g study.html > ../study.html
sed s#/style.css#/blog/styles_zh-cn.css#g unicode_java.html > ../unicode_java.html
sed s#/style.css#/blog/styles_zh-cn.css#g weblog.html > ../weblog.html
sed s#/style.css#/blog/styles_zh-cn.css#g weblucene.html > ../weblucene.html
sed s#/style.css#/blog/styles_zh-cn.css#g xml_potato.html > ../xml_potato.html
sed s#/style.css#/blog/styles_zh-cn.css#g xslt.html > ../xslt.html
3 然后执行脚本文件:
shell sed.sh
大辉的这套MT模板设计的很不错,我看到在很多MT的用户中都有传播。这套模板不可避免的也继承了原有MT模板的一些缺陷,而且还闹出了不少误会,一段时间以来我一直会收到: “你好Annie,能将《蓝海战略》这本书的电子版给我发一份吗?”的留言,问题就是出在MT的模板的段落设计上:
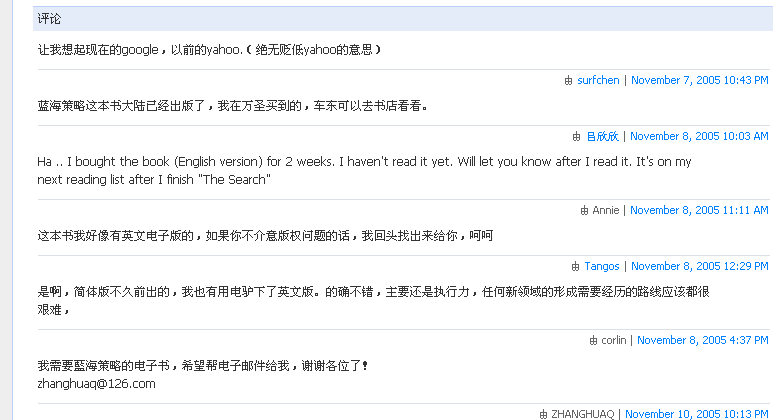
有电子版的留言是四楼未完成的Tango写的,但是由于那条华丽分割线,很多人都以为是“楼上”的Annie发表的,大家把这里当成论坛了吗?
将这个问题写给了大辉,我自己已经把他给修正了,同时修正了在FireFox下字体不像IE下那么圆滑的问题。
diff -b dbanotes.css styles-site.css
774c775
< border-top:1px solid #dae0e6;
---
> border-bottom:1px solid #dae0e6;
777c778
< font-size:11px;
---
> font-size:12px;
Apache上的防mp3盗链的参考配置如下:
RewriteEngine on
RewriteCond %{HTTP_REFERER} !^http://(www\.)?niernier\.com/.*$ [NC]
RewriteRule \.(mp3|rar)$ http://www.niernier.com/archives/000445.html [R=301,L]
#RewriteLog "logs/rewrite.log"
#RewriteLogLevel 3
功能:
不仅屏蔽/禁止非本网站的盗链访问,还将盗链请求转给自身的网站,让读者知道谁是真正的原创作者。
说明:
RewriteCond 条件:意思就是所有的mp3和rar访问如果referer不是本网站niernier.com或www.niernier.com,
RewriteRule 规则:自动转向到原作宿主页: http://www.niernier.com/archives/000445.html
注释掉的部分是测试rewrite engine用的:对于调试mod_rewrite很有用。
效果:字节流量比原来下降一半,网站独立用户访问量上升了1倍
日期 参观人次 网页数 文件数 字节
2006年 十一月 16 685 897 4641 865.99 M字节
2006年 十一月 17 728 1173 5522 1.28 G字节
2006年 十一月 18 648 934 5535 1.46 G字节
2006年 十一月 19 704 1020 7120 1.40 G字节
2006年 十一月 20 882 1176 5286 1.23 G字节
2006年 十一月 21 2380 3526 6076 568.01 M字节
2006年 十一月 22 2146 3003 5791 458.13 M字节
2006年 十一月 23 2092 3177 6131 518.99 M字节
具体的数据和商业模式分析附后:
大辉写过一篇:技术资料过载 - DBA notes,我也有同感,自己也找了一些方法解决,列举如下。
1 可搜索:尽量利用网上的资料而不是本机离线手册,在网上在线手册除了更新快外,可搜索性也是很重要的一点,在线文档通过搜索引擎查起来更方便。尤其是很大的PDF文档,尤其不便于检索,而大部分时候可能只需要找的是其中的一章或者一个函数说明;
2 抛砖引玉:尽量使用带有用户反馈的在线手册,现在很多官方的在线的文档都有评论注释机制,有些带有用户们的反馈例程,比如PHP:http://www.php.net/fwrite,而且相对错误也比较少;
3 速查卡片:将常用而又记不住的命令做成卡片和速查手册:并打印出来,之前我写的一些文档,最初就是记录在电子日记簿中的常用命令速查。我也非常喜欢搜集并打印出很多常用工具的快捷键reference card;
正则表达式用了几年了,本以为这个问题很简单:把所有查询关键词中纯英文(包括数字)的滤出来;但是折腾了一下午才总算找到了以下解决方法:
iconv -f gbk -t utf-8 query_list |egrep -e "^[a-z0-9]*$"
1 为什么需要用utf-8: 如果直接对gbk编码的文字进行grep会由于编码中的交叉而滤出很多中文;
2 为什么需要用egrep: egrep=grep -E 就是正则表达式支持扩展字符集,扩展的正则支持用高八位字符;
关键:先将文本强制转换成UTF-8,然后利用egrep。
适用环境:Unix命令行模式下的grep;
有更简单的方法吗:请留言……
Host Loss% Snt Last Avg Best Wrst StDev
1. 60.195.249.1 0.0% 41 0.3 2.2 0.3 71.5 11.1
2. 202.99.57.129 0.0% 41 0.3 0.3 0.2 1.5 0.2
3. 202.99.57.9 0.0% 41 0.7 19.9 0.6 189.6 46.8
4. 221.239.18.133 0.0% 41 3.2 3.4 3.2 3.7 0.1
5. 221.239.7.49 0.0% 41 3.0 2.8 2.7 3.2 0.1
6. 221.238.222.209 0.0% 41 2.7 14.2 2.7 131.5 29.9
7. 202.97.34.225 0.0% 41 22.7 23.0 22.6 29.0 1.0
8. 202.97.37.53 0.0% 41 22.7 34.5 22.6 180.6 37.1
9. 202.97.33.10 0.0% 41 23.1 22.9 22.7 23.6 0.2
10. 202.97.33.54 0.0% 40 24.4 31.6 23.1 44.9 6.0
11. 202.97.4.46 0.0% 40 58.0 58.3 58.0 60.8 0.4
12. 216.239.47.237 12.5% 40 188.2 189.2 188.0 204.6 2.8
13. 72.14.239.13 10.0% 40 191.7 191.8 191.1 193.5 0.5
14. 72.14.233.55 7.7% 40 192.0 191.4 190.7 192.2 0.4
15. 72.14.233.118 12.5% 40 242.8 243.1 242.4 244.8 0.6
16. 72.14.236.183 7.5% 40 243.7 243.5 242.3 250.9 1.6
72.14.232.113
17. 66.249.94.118 22.5% 40 242.7 247.9 242.7 255.7 4.5
72.14.236.13018. eh-in-f99.google 10.0% 40 242.7 243.3 242.6 246.0 0.6
从搜索前端服务器到Google的XML接口之间的路由,和各个路由点的响应时间(包括最短,最长,平均)及丢包率一目了然。
利用报表中的提示搜索了一下,发现了mtr这个工具,以前需要多个ping和traceroute 命令实现的统计,用mtr集成在了一起。
WinMTR就是MTR工具的Windows窗口客户端,非常适合Windows用户做路由跟踪。
下载地址:winmtr.sourceforge.net
前2天尝试awstats的按天归档机制,发现忽然需要给统计报表应用做一个日历,每天链接到报表的URL。在网上搜了几套PHP的日历库:发现PHP Calendar是一个最方便的可扩展PHP类包,我需要的2个功能都非常容易方便的定制功能都有了:
1 按月/按年的日历展示;
2 可以定制日期链接到指定的URL地址;
一个简单的月历输出样例在这里:
include 'Calendar.php';$today = date('j');
// Customize the date links to digest/yyyymmdd.html
class MyCalendar extends Calendar {
function getDateLink($day, $month, $year) {
global $today;
$link = "";
if ( $day < $today ) {
$link = "/digest/" . date("Ymd", mktime(0, 0, 0, $month, $day, $year)) . ".html";
}
return $link;
}
}$cal = new MyCalendar;
// First, create an array of month names, January through December
$chineseMonths = array("一月", "二月", "三月", "四月",
"五月", "六月", "七月", "八月", "九月",
"十月", "十一月", "十二月");// Then an array of day names, starting with Sunday
$chineseDays = array ("日", "一", "二", "三", "四", "五", "六");$cal->setMonthNames($chineseMonths);
$cal->setDayNames($chineseDays);
// Week start from Monday
$cal->setStartDay(1);echo $cal->getCurrentMonthView();
CSS配置:
.calendarHeader {
font-weight: bolder;
color: #CC0000;
background-color: #FFFFCC;
}.calendarToday {
background-color: #FFFFFF;
}.calendar {
background-color: #FFFFCC;
}
输出:
1 首页的右上角,给我之前做的Lilina归档器的输出做了一个本月的归档日历;
2 给从2005年5月3日以来的归档做了一个按年的浏览页,PHP源代码在这里:http://www.chedong.com/digest/index.php/source
其实很多日志统计都是按天输出的文本: xxx_yyyymmdd.txt 利用日历归档机制可以很方便的实现导航留言,也不用报表阅读者手工输入日期了。
拖了3年了一直没做的一件事情:将以前tech/目录下的内容进行结构化管理,今天终于完成了。
4年前觉得自己做的这几个网页就是blog,从现在看,缺少了很多特征:可留言反馈,可RSS发布等。所以这次重构的系统选择我提出了以下几个要求:
1 文章按照指定文件名在根目录下导出:保持原有的链接不变(permalink);
2 模板话管理:省却使用sed批量替换的麻烦,内容和表现分离;
3 在线可编辑,而不是使用SFTP/FTP上传;
4 更好的管理文章之间的关联;
5 有反馈机制:留言,这对内容的修正很有好处;
最后终于选择了熟悉的MovableType通过一番设置,用了2个周末下班时间完成了。对mt的设置如下:
1 只保留首页/归档页 使用 %f 模式自定义文件名;
2 取消按月归档,取消按分类归档;
3 使用RelatedEntry插件实现标签分类;
同时也发现MT的一个缺点: 不能管理过长的文档(超过20k的),比如: Hello Unicode这篇文章中的3个实验不得不分拆离成了3篇文章;
现在chedong.com 主要有3个目录:都已经是结构化的数据了。
blog/ 个人blog
tech/ 笔记
digest/ 文摘收藏归档
最近有很多国内的朋友都在问:FlickR.com怎么看不到照片,FlickR.com打不开,图片无法显示等问题。昨天在KReny的网站上看到了用FireFox插件可以解决这个问题的方法,只需要安装FireFox后:
到下载Access Flickr 插件: https://addons.mozilla.org/en-US/firefox/addon/4286并重启FireFox浏览器即可。
如果有朋友需要看你的Flickr相册:请赶快将这个方法告诉他。
5月份参加了2个会议: Alibaba:侠客行和厦门的搜索引擎战略大会, 近期有时间会将相关的笔记整理一下.
Rasmus是PHP项目的创始者之一, 我听了他做的关于web应用安全性检查的讲座, 印象比较深的一点: 任何参数的输入都需要进行安全校验: 只要是有用户输入未来将会进行web输出的地方, 就要防止用户输入: ><img src=1 onerror=javascript:alert(document.cookie)< 这样的代码, 从而出现XSS漏洞; 各种类型的数据都可以找到相关的安全检查包和过滤函数, 比如: intval()就是很常用的一个针对整数类型的参数校验的方法;
而做为个人用户面对这个不太平的互联网, 使用多个浏览器, 将生活(商业)和工作分开(这也相当于在2个独立的用户空间访问互联网) 也是一个比较好的安全之道, Rasmus Lerdorf自己用的是Mac: 于是: 个人/商业(比如信用卡之类的信息) Safari 而工作和其他网站访问 使用FireFox.
晚上的酒吧聚会上, 我问了Rasmus一些关于开源社区的问题:
做为发行量很大的IT开发人员工具参考书出版商,O'Reilly的书往往紧跟开发人员的需求,与时俱进,一版而再版,这本《精通正则表达式》已经是第三版了,看了一下目录:
增加了对Unicode的支持;
增加了不少在新语言环境中的运用介绍: PHP、Java、dotNET等(Ruby没有单独列出一章只是讲原理的时候提到);
利用正则表达式可以方便的解决大量文本高级替换整理工作:从把文章中的华氏度换成摄制度到按照指定公式生成各种统计报表,而最近几年:搜索引擎对于互联网的影响加大,为了更好的伺候搜索引擎蜘蛛和机器人,连SEO的培训中:往往也会增加基于正则表达式的url rewrite一节。所以这里向原作者提个建议:希望在下一版中增加基于Apache的mod_rewrite进行URL rewriting一章,相信会吸引更多的LAMP开发人员。
《精通正则表达式》第三版(中文) 的翻译者是余晟(目前在抓虾工作)。本书发行后,译者会在blog上开辟一个专门的勘误专区吧……
我个人的一些使用感受附后: 最后希望大家支持正版,远离盗版非法电子书下载;
如果担心自己网站/Blog内容遇到不可抗力的用户可以考虑一下利用s3的服务将文件远程备份到国外。去年AMazon推出了一系列基于Web的服务,其中S3(Simple Storage Service)是网络服务的存储和带宽传输,发布时的价格为:
# $0.15 per GB-Month of storage used.具体成本可以参考一下Jeremy的在家备份和使用S3的比较,算算电费和灾难恢复等可靠性指标还是用s3比较便宜,其实我自己目前也在用DreamHost的空间做远程定期同步备份。
# $0.20 per GB of data transferred.
注释:带宽费用国内大约1¥可以买2-4G,国外的带宽还是比较贵的。
由于是公开的web服务: 现在的可用工具也很多了。从面向个人用户的客户端程序(Java的客户端JetS3T和不免费的JungleDisk),到面向自动备份的脚本,也有用于应用开发的各种语言样例; 从国内访问,速度是无法保证的,因此远程安全备份和用于自己在不同机器上共享文件就是主要的目的了,自动备份文件有文章推荐了s3curl,我下载用了一下,需要用到的就是以下几个命令: s3curl就是在curl命令外面包了一个选项的perl脚本,登录Amazon的s3服务,先从Your Web Service Account菜单进入到AWS Access Identifiers,获得你的Your Access Key ID Your Secret Access Key 。
列表:
./s3curl.pl --id YourAccessKeyID --key YourSecretAccessKey -- http://s3.amazonaws.com
创建目录[Bucket]:Bucket就是文件夹,但是不能在文件夹下再创建文件夹。
./s3curl.pl --id YourAccessKeyID --key YourSecretAccessKey --createBucket -- http://s3.amazonaws.com/chedong
上传文件[Object]:
./s3curl.pl --id YourAccessKeyID --key YourSecretAccessKey --put mysql.4.gz -- http://s3.amazonaws.com/chedong/mysql.backup.gz
./s3curl.pl --id YourAccessKeyID --key YourSecretAccessKey -- http://s3.amazonaws.com/chedong
注意:
请预先确认已经安装 perl -MCPAN -e 'install "Digest::HMAC_SHA1"'
最近才了解并开始使用svn ,其实和cvs的操作还是略有一些差别的。cvs其实很多功能是rcs和其他一些系统命令的组合;svn中的diff 如何忽略空格,就不像cvs diff -b一样能忽略空格来比较文件的差别。 而svn help说的:
svn diff -x [--extensions] arg : Default: '-u'. When Subversion is invoking an
external diff program, ARG is simply passed along
to the program. But when Subversion is using its
default internal diff implementation, or when
Subversion is displaying blame annotations, ARG
could be any of the following:
-u (--unified):
Output 3 lines of unified context.
-b (--ignore-space-change):
Ignore changes in the amount of white space.
-w (--ignore-all-space):
Ignore all white space.
--ignore-eol-style:
Ignore changes in EOL style
$ svn diff -x -b
svn: '-b' is not supported
[helpers]
diff-cmd = /usr/bin/diff
以上例子中svn的版本: svn, version 1.4.2 (r22196)
compiled Feb 3 2007, 12:58:02
今天收到一封垃圾邮件:但是在GMail中居然直接就显示了邮件中的图片。我手工标记垃圾邮件后很奇怪:为什么GMail对一封垃圾邮件未经就允许显示图片了呢?
后来看了邮件的信息发现: 这个垃圾制造者的发信人写的地址是我的邮箱地址。利用了GMail等很多邮箱的可信任邮件地址的机制,每个人的可信任发件人列表都不一样,但邮箱主人自己很有可能给自己发过邮件(比如用于备份照片之类的)。所以声称发信人是你自己的时候:就有很大概率是可以显示图片,于是图片请求就被发出了,同时发送给spammer服务的还有你的浏览器信息,来源地址(mail.google.com)等;
最近看到了一些关于Google Account的潜在XSS风险的报道,其实任何一家的服务,安全风险都是存在的,关键的问题是当你对一个服务或者帐号产生很大依赖的时候,进行一次丢失密码的演习还是非常有必要的。Google account可以通过邮箱安全问题和备用邮箱找回忘记的密码,但是被盗的确就比较麻烦了。
上海互联网同行经常能有一些很务实交流,比如:VeryCD向博客大巴介绍过Google的免费企业邮箱的注册方法和CDN服务商, 而同客齐集的交流中我向王建硕请教过:微软是如何量化开发人员的工作饱和度,评估开发人员的工作效率并鼓励开发者按时完成任务的?从后来通过对BugFree这套系统的使用交流中了解了一些考核机制在任务跟踪系统中影响这些因素的方法。
如果说GTD是一个人的目标管理,那么任务跟踪系统就是帮助实现团队的目标管理: 而且一件事情同时被多个人跟踪,还是非常有助于减少任务的被跟“丢”几率的,一个任务的角色有任务的创建者(甲方)和任务执行者(乙方)两个角色; 而开发团队一般会有3个角色来进行任务的跟踪,项目的发起者(产品经理),项目的执行者(开发人员),项目的确认(测试人员),而一个任务按照进行中,完成确认,关闭这几个状态,也有发起时间(创建者),解决时间(执行者),完成确认时间(创建者)这几个关键时间点, 利用这几个时间因素结合创建人,创建原因等因素,通过BugFree的查询生成器可以完成很丰富的开发过程指标统计甚至完成一些初步的KPI考核指标统计;
开发人员的工作饱和度
就是简单的任务量累计,按照每个需求的预算时间进行累加,比较开发人员的工作时间;
任务的平均关闭时间
总工作时间 ÷ 关闭的任务数,用于评估开发人员的工作效率;
1 开发人员不要将手边积累过多的任务,从而让大量的任务处于等待状态;
2 开发人员会要求需求人员尽量将任务分解: 不要有超过2天的任务,便于及时的确认进展;
3 开发人员完成任务后主动告知需求人员,尽快确认完成并关闭任务;
项目响应速度
项目无更新时间不得超过一定时间(比如: 24小时) ,就是统计:项目状态不等于关闭, 最后更新时间相比现在大于24小时的任务,每天统计:被发现就要发出警告相应项目的执行者; 即使项目没有完成,也要通过编辑项目向项目的发起者进行反馈,避免任务被长期无响应状态;
为此: 项目的开发者还需要遵循以下规则;
1 跟踪系统本身只是用于备忘和时间的统计,任务完成还是需要同事间直接(最好是面对面的)交流;
2 项目的执行方不能关闭任务,只能由创建者关闭;
3 执行者另外需要其他开发人员帮助的时候,需要开启新的任务作为咨询;
4 任务类型只计算新增需求,旧需求的错误修正,不计算为工作时间;
设计以上的规则的目的是:
开发者:作为任务的执行者在任务启动后应及时的解决并要求创建者关闭任务,开发者会尽可能多和任务的创建者沟通,尽可能在项目进入任务跟踪前将项目的需求细化并在完成后及时提交测试并关闭,从而达到满足工作工作饱和度的同时,减少单项目完成时间指标;
需求人员:细化需求合理估算工时避免返工,因为项目的执行者是不用对项目需求的合理性负责的,按时开发完毕后因为需求设计错误为开发者计入工作时间,让需求的提出者(产品经理)成为项目风险的承担者,从而避免产品经理即无责任也无权利的状态;
此外: 什么指标可以体现开发者除了完成任务本身外还在不断找新方法提高效率呢?
上周末在博客大巴邀请了上海几家StartUp公司的朋友做了一次技术交流:VeryCD的科学家们,客齐集,联络家,CDNUnion,安居客和Sun的Startup解决方案专家;
主题1:动态内容的CDN缓存
结论,目前CDN缓存仍然以静态内容为主,动态页面缓存过期/更新策略较复杂;而CDN有purge接口,但现在实际应用较少: 更多缓存服务是为内容永不更新的图片、视频等服务;此外,固态盘代替逐步内存的可能性近期还没有,固态硬盘的仍然价格非常高,I/O的速度也是问题;
主题2: Memcached的使用
所有网站都用了Memcached,并通过避免对数据库的连接而大大提高了性能(命中率一般在90%以上);
关于:多memcached的分布策略;
客齐集
规模: 在多台前端应用服务器上划出一定空间,
分布规则:使用的是memcached addserver方式由memcache自己进行缓存分布;
单点失败处理:遇到个别节点中断会retry;
博客大巴和VeryCD应用类似:
规模: 几十G(单个2G);
分布规则:都是自己应用设置设置缓存分布规则,对数据进行分布,
单点失败处理:如果遇到Memcached中断并不尝试其他服务器;
关于memcache的压缩:
PHP客户端可以设置压缩外, server端也有更详细的压缩配置选项(memcached的文档中有?);
关于memcached的扩展性: 最新版本有考虑consistent hash(在扩展服务节点后,旧内容仍然再旧服务器上,不用按重新按新的分布规则生成新缓存)
memcached: bin模式存储;
对于缓存对象:大的List列表页对象用memcache缓存对效率提升很重要;
主题3: Start up公司的招聘来源
客齐集的校园招聘成果还是让其他公司非常的眼红,另外说一句: 我们仍然在招前端应用开发人员(欢迎应届生):有优秀的开发人员,各个Startup公司之间都是可以推荐的(VeryCD的51job招聘广告就是托管在博客大巴的),以后还会不定期做一些交流。
上周又召集上海互联网小业主做了一次山寨技术交流会,前3次都是博客大巴做东; 这次的一个主题由Sun的工程师向我们介绍了:Web20kit,并征求反馈意见;
觉得对于小网站来说: 最需要的是以下几类技术/服务
1 可扩展的存储硬件或服务:目前大部分公司还是用nfs+盘阵的模式做存储,在备份/容量扩展方面,很多都是需要结合应用修改来实现的,如果Sun能在国内做Amazon S3那样的存储中心,我们还是信得过的;
2 全文检索Lucene应用包: 对于很多以PHP为主要开发工具的小公司来说,只是为了lucene掌握java成本还是比较高的,之前我尝试过XML接口,现在感觉有一个Json in / Json out的方案也是会很有用的;
3 关键词过滤引擎: 其实旁路监听,动态屏蔽的模式已经是非常先进的理念了,昨天见了一次Rebecca,过滤需求其实是非常有中国特色的;
4 系统安全检查咨询:FABAN能否扩展为一个安全漏洞检查工具?安全的检查也是我们非常关心的;
5 MySQL 急救中心: 大部分网站出了数据库问题的时候已经没有时间学tracking tool了,SUN的工程师赶快过来吧,如果最后能解决1500¥/小时也是有市场的;
在前一期山寨交流会上:桂新说他会将良好的构架和一套完整的监控系统作为两个非常重要的基础来抓,良好的架构一步到位这点很难做到(对于发展速度并不确定的小公司来说,架构过大也是一个成本上的风险),但对于后者:一套完整监控系统我是非常认同的。对于目前普遍缺乏测试的Web应用开发过程来说,监控几乎就是测试很重要的一部分;而系统监控本身,也可以帮助及时发现很多问题并量化优化的效果。而系统的扩展和调优的大部分技巧都可以从《构建可扩展的Web站点》(作者是Flickr的开发者)一书中看到。为了减少不必要的调优(盲目的调优是危害很大的),建议从这2章开始看起: 第8章《瓶颈》发现和第10章《统计数据,检测和报警》;有了这些瓶颈检查结果和统计监测/报警系统后,再有针对性的看其他章节做系统调优。
以下是我在博客大巴开发中的一些实践小结:
1 数据库相关
1.1 系统应用层面出问题我一般都习惯性的先去看数据库群的连接数统计:大部分应用最后的瓶颈都在于单表数据量过大后,数据存取慢导致的并发连接数过多的问题,
1.2 解决这个问题目前的主要策略就是分片(share nothing),单个数据库连接数超过100,就想办法拆分并用多个daemon提供服务,数据的拆分也降低了单表的数据量;
做个实验:
单个用户名密码表1000万数据(单个deamon 单个数据库) 可以承受多大的QPS(负载单位:query per second)?
将这个表:存储到10个Deamon 10个数据库 10个表中,单表的记录数会降低3个数量级(千万级==> 万级) 这样的情况下,可以承受多大的QPS?
1.3 对于需要全局访问的数据(比如做每天的汇总统计),可以通过另外冗余存储一份专门用于全局对比的操作用(会增加一定应用为保持数据一致性所带来的开发量);
1.4 slowquery一般是遇到问题才去看的,其实binlog转换成文本格式后,也可以用mysqldumpslow统计的,slowquery就是执行时间超过一定阈值(缺省是1秒)的binlog,更全面查询统计,则需要打开数据库的query log,binlog其实就是没有只读操作的querylog;
2 日志相关
2.1 对于应用来说:容忍过多的非致命错误容易让错误日志变得非常难读,从而对发现很多致命错误造成麻烦;在各种系统开发间隙,统计各种错误日志也是我非常乐于去做的一件事儿,从warning faital级的PHP错误信息到404错误日志;报警后的急救车固然重要,日常的体检及时发现潜在风险较高的漏洞或缺陷并修正都会在系统真正发生报警的时候为成功抢修节约大量时间;
2.2 经常出问题的环节要有错误日志,并且格式设计的比较便于sort和grep也是很重要的一方面;
3 需求削减:
3.1 并非所有用户都需要被满足: 发现spammer和盗链者,并设法降低资源流失的速度;
3.2 通过日志统计发现用户使用较少但对系统负载很高的功能;
此外:一个管理方面问题: 开发过程本身是日志是最少的,怎么解决?
图片服务的特点就是:不修改,少量新增/极少删除,存储量大,需要尽量避免迁移和复制;旧的集群锁定后:对于原来的文件基本上就只删不增了;虽然目前有很多开源的分布式文件系统,但是目前比较便宜的解决方法还是本地硬盘服务器不断一组一组的增加,相互备份的一组服务器作为基础存储,然后前端使用缓存服务器;通过LVS或者CDN进行负载/分布的均衡。
目前一台服务器配上T的存储也相对比较便宜;关键是如何尽量避免使用NFS进行使用;目前我们选择的办法是:图片服务器一组使用2台,一组服务器之间使用NFS相互mount用于备份;另外有上传文件服务器会NFS访问;对外服务文件使用Web服务器负载均衡。而在2台服务器上,会给予基于ID将用户的图片进行存储,存储的分布化会遇到一个问题:固定存储空间随着时间增加再次达到系统的空间/负载的瓶颈。观察了一下Flickr的图片存储地址:好像是在定期启用新的集群,各个时期的域名分布如下:
http://farm1.static.flickr.com 2006年中以前;
http://farm2.static.flickr.com 2006年底;
http://farm3.static.flickr.com 2007年底;
http://farm4.static.flickr.com 2008年底;
user_foo - farm1.static....../20060124_003.jpg
\ farm1.static....../20060324_005.jpg
\ farm1.static....../20060824_021.jpg
\ farm2.static....../20070124_006.jpg
\ farm3.static....../20080124_002.jpg
\ farm4.static....../20081124_001.jpg
另外如果希望前端存储使用的域名一直保持不变,通过目录规则进行rewrite的方式也是可以的,比如:将要发布的内容,后端按时间建立一个域名进行存储;
200711.foo.example.com
200712.foo.example.com
200801.foo.example.com
...
200811.foo.example.com
foo.example.com/200711/ >> 200711.foo.example.com
foo.example.com/200712/ >> 200712.foo.example.com
...
foo.example.com/200811/ >> 200811.foo.example.com
这样就简单的实现了图片存储随时间增加而扩展的,每隔一定时间将上传服务器指向到新的服务器集群;
年初的时候收藏过一篇关于mysqlreport的报表解读,和内置的show status,和show variables相比mysqlreport输出一个可读性更好的报表;但Sundry MySQL提供的脚本相比mysqlreport更进一步:除了报表还进一步提供了修改建议。安装和使用非常简单:
wget http://www.day32.com/MySQL/tuning-primer.sh
chmod +x tuning-primer.sh
./tuning-primer.sh
[client]
user = USERNAME
password = PASSWORD
socket = /tmp/mysql.sock
样例输出:在终端上按照问题重要程度分别用黄色/红色字符标记问题
-- MYSQL PERFORMANCE TUNING PRIMER --
- By: Matthew Montgomery -MySQL Version 5.0.45 i686
Uptime = 19 days 8 hrs 32 min 54 sec
Avg. qps = 0
Total Questions = 264260
Threads Connected = 1Server has been running for over 48hrs.
It should be safe to follow these recommendationsTo find out more information on how each of these
runtime variables effects performance visit:
http://dev.mysql.com/doc/refman/5.0/en/server-system-variables.html
Visit http://www.mysql.com/products/enterprise/advisors.html
for info about MySQL's Enterprise Monitoring and Advisory ServiceSLOW QUERIES
The slow query log is NOT enabled.
Current long_query_time = 10 sec.
You have 0 out of 264274 that take longer than 10 sec. to complete
Your long_query_time may be too high, I typically set this under 5 sec.BINARY UPDATE LOG
The binary update log is NOT enabled.
You will not be able to do point in time recovery
See http://dev.mysql.com/doc/refman/5.0/en/point-in-time-recovery.htmlWORKER THREADS
Current thread_cache_size = 0
Current threads_cached = 0
Current threads_per_sec = 1
Historic threads_per_sec = 0
Your thread_cache_size is fineMAX CONNECTIONS
Current max_connections = 100
Current threads_connected = 1
Historic max_used_connections = 33
The number of used connections is 33% of the configured maximum.
Your max_connections variable seems to be fine.MEMORY USAGE
Max Memory Ever Allocated : 96 M
Configured Max Per-thread Buffers : 268 M
Configured Max Global Buffers : 7 M
Configured Max Memory Limit : 276 M
Physical Memory : 1.97 G
Max memory limit seem to be within acceptable normsKEY BUFFER
Current MyISAM index space = 8 M
Current key_buffer_size = 7 M
Key cache miss rate is 1 : 1817
Key buffer fill ratio = 6.00 %
Your key_buffer_size seems to be too high.
Perhaps you can use these resources elsewhereQUERY CACHE
Query cache is supported but not enabled
Perhaps you should set the query_cache_sizeSORT OPERATIONS
Current sort_buffer_size = 2 M
Current read_rnd_buffer_size = 256 K
Sort buffer seems to be fineJOINS
Current join_buffer_size = 132.00 K
You have had 0 queries where a join could not use an index properly
Your joins seem to be using indexes properlyOPEN FILES LIMIT
Current open_files_limit = 1024 files
The open_files_limit should typically be set to at least 2x-3x
that of table_cache if you have heavy MyISAM usage.
Your open_files_limit value seems to be fineTABLE CACHE
Current table_cache value = 64 tables
You have a total of 125 tables
You have 64 open tables.
Current table_cache hit rate is 9%, while 100% of your table cache is in use
You should probably increase your table_cache
TEMP TABLES
Current max_heap_table_size = 16 M
Current tmp_table_size = 32 M
Of 564 temp tables, 6% were created on disk
Effective in-memory tmp_table_size is limited to max_heap_table_size.
Created disk tmp tables ratio seems fineTABLE SCANS
Current read_buffer_size = 128 K
Current table scan ratio = 1 : 1
read_buffer_size seems to be fineTABLE LOCKING
Current Lock Wait ratio = 0 : 264392
Your table locking seems to be fine
更有用是作者总结的处理MySQL性能问题处理的优先级:尤其是头3条,基本上可以解决大部分瓶颈问题的原因。
# Slow Query Log 慢查询 尤其是like操作,性能杀手,轻易不要使用,让全文索引交给Lucene或者利用Tag机制减少like操作;
# Max Connections 并发连接数:一个MySQL deamon缺省最大连接数是100,调到更高只是为了出现问题是给我们更多的缓冲时间而不是任其一直处于那么高的状态,并发连接数类似于等候大厅:当等候人数过多的时候,一味扩大等候厅不是根本解决问题的办法,提高业务的处理速度,多开几个窗口才是更好的解决方法;我的经验就是超过100: 数据就要想办法(镜像或者分片)分布到更多Deamon上;
# Worker Threads: Jeremy Zawondy 曾在部落格上說到:Thread caching 並不是我們最需要關心的問題,但當你解決了所有其他更嚴重的問題之後,它就會是最嚴重的問題。(thread caching really wasn't the worst of our problems. But it became the worst after we had fixed all the bigger ones.)
# Key Buffer
# Query Cache
# Sort Buffer
# Joins
# Temp Tables 临时表
# Table (Open & Definition) Cache 表缓存;
# Table Locking 表锁定
# Table Scans (read_buffer)
# Innodb Status
日志统计和各种负载监控:
AWStats
全面统计原始日志,分析浏览器和非浏览器的流量,在很多应用中蜘蛛抓取已经超过了浏览器访问; 而搜索引擎的来源也和蜘蛛的遍历有很大的关系; 使用Cacti对服务器的各种指标进行监控,对于系统优化重构后的跟踪也有非常直观的表现,页面YSlow得分,甚至Google Webmaster统计都会比较有用; 进行重构前先进行一些统计和分析工作,在重构后也便于评估和量化重构的效果。
前端优化: Nginx
对照YSlow进行前端优化的主要是:
实现统一的expires配置: 实现客户端的缓存;
解决HTTP压缩: 减少文本的传输;
解决日志问题:更方便的增加针对cookie等字段的记录;
通过代理实现实现负载均衡: 将原有单机应用通过路径规则分布到后台多台应用服务器上而不用增加域名;
解决URL Rewrite等问题:相比IIS自身,nginx的配置都相对简单;
缓存优化:
静态文件缓存服务器:Varnish
分布式应用缓存: Memcached;
epoll推动web发展:在各种服务中都能看到epoll机制的影子;
而各种平台之间的数据交换尽量使用json XML等格式便于未来跨平台调用;
面向机器的抓取优化
1 缺省域名唯一化:缺省foobar.com 设置301跳转到 www.foobar.com 一方面减少搜索引擎页面消重的负担,一方面可以将针对相同内容的反向链接权重汇总。对于缺省使用https访问的网站,如果不跳转(比如以前的支付宝),往往还会有浏览器提示安全证书路径不匹配的问题; 另外: 在Google Webmaster tools中也有缺省域名的配置;
2 被遗忘的流量:想办法搜集域名解析失败和拼写错误导致的流量流失;曾经启用过的域名,就尽量不要删除,一直保留并设置转向到最新的地址;有渠道取到DNS的这种记录吗?
3 404页面的运营:返回hard 404(返回http header而不是html 404 header),统计并跟踪带有referer的404日志,修正这些问题;
4 节省HEAD类请求:对于一些蜘蛛(主要是百度蜘蛛),经常使用head请求来检查旧链接的有效性,启示可以针对这些请求做直接返回304处理,以节省服务器的处理资源;
5 永久转向:避免302,转向尽量使用301到最终地址;
6 重视站内搜索: 利用搜索做内容之间的关联和发现,每篇文章提供相关文章等功能;而能解析出搜索来源关键词的404访问尤其应该通过站内搜索为用户提供其他可选内容。
7 利用google webmaster tools等跟踪收录和错误抓取问题并及时修正;
8 归档页面URL标准化:虽说搜索引擎声称动态页面和静态页面收录和RANK不受影响,但为了方便管理,最好还是将内容页面尽量标准化成静态地址,并页面中尽量加上唯一化的地址,减少搜索引擎抓到相同内容的不同链接后消重的麻烦,比如各种论坛的内页: <link rel="canonical" href="http://www.example.com/discuz/thread-405413-1-2.html" />
面向用户的内容优化
1 自身主动检查spam,防止大量的镜像内容,搜索引擎对于spam处理不利的站点,往往也只好使用整体降权的方式;
2 避免用户因为使用第三方计数器,JS小功能(比如:样式很炫的用户鼠标指针等)被植入病毒木马,Google会向比较严重的站点的webmaster@信箱发送邮件提醒相关问题,所以这个邮箱一定要创建并定期查看;
3 结构化数据源: RSS、sitemaps归档入口,而最高效率的是利用各种ping接口将最新内容即时发送给搜索引擎(最近百度也都支持相应接口和协议了);
4 重视标题和meta description在搜索结果页上的可读性: meta description不参与排序,但良好的标题和meta description往往比纯算法提示出来的摘要更接近用户目标,在现有排名位置下,争取吸引用户更多的点击也是一个有效的策略;
5 应有的反向链接的获得: 主动加上版权声明;
记录一下纪念浪费的3个小时,在新的Mac上发现之前的tunnel脚本都不能用了,总是提示错误:
....
sys_tun_open: /dev/tun0 open failed: No such file or directory
....
Tunnel device open failed...
Could not request tunnel forwarding...
对照了之前的笔记本,发现原来是不必要的把 /etc/ssh_config 里这行启用了:
Tunnel yes
恢复成初始设置后恢复:
# Tunnel no
按此阅读全文 "ssh: sys_tun_open: /dev/tun0 open failed: No such file or directory 问题的解决" »
遇到Contral-A ^A的分隔符:
awk -F '\1' '{print $1,$3}' foo.log
awk '{print "\001\002\3\4\005\06\07"}' bar.log |more
会得到:
^A^B^C^D^E^F^G
^A^B^C^D^E^F^G
按此阅读全文 "特殊字符Ctrl-A Ctrl-B Ctrl-C Ctrl-D Ctrl-E Ctrl-F分隔符在awk中的输入" »
Referer丢了会导致很多来源分析就做不了了,以前referer丢失来源有三种:
0 代码因素:一些js构造链接打开的模式会造成referer丢失,解决方法是尽量避免windows.open meta refresh等;
1 代码+浏览器因素:meta js打开新窗口 部分浏览器会丢失
2 协议因素:https协议降级http,解决的方法是靠https端增加声明,比如:通过meta的方式:referer meta
<meta name="referrer" content="no-referrer|no-referrer-when-downgrade|origin|origin-when-crossorigin|unsafe-url">
现在有多了几种:主要来自多核浏览器使用率的增加。
3 多核浏览器切换内核/隐私浏览模式,部分第三方浏览器版本会丢referer,360支持renderer 标签,可以强制使用某种内核进行页面渲染,比如:webkit。
4 浏览器的各种鼠标手势等高级功能,会丢失referer,
5 来自移动app:微信 微博的点击;
按此阅读全文 "浏览器中丢失referrer和HTTPS=>HTTP丢失referer的解决:基于会话的站内来源地址URL还原" »
此页面包含了发表于 车东[Blog^2] 的 技术笔记|Tech Notes 所有日记的归档,它们从老到新列出。
前一个分类 MovableType|MT。
后一个分类 搜索引擎动态|Search Engine。



