最近搜集RSS解析工具中找到了MagPieRSS 和基于其设计的Lilina;Lilina的主要功能:
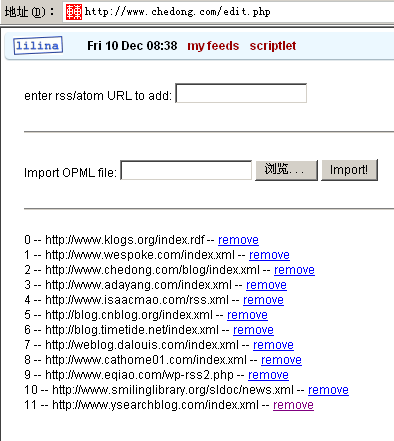
1 基于WEB界面的RSS管理:添加,删除,OPML导出,RSS后台缓存机制(避免对数据源服务器产生过大压力),ScriptLet: 类似于Del.icio.us it的收藏夹即时订阅JS脚本;
2 前台发布:将自己的首页改成了用Lilina发布我常看的几个朋友的网志,也省去了很多更新自己网页的工作,需要php 4.3 + mbstring iconv
开源软件对i18n的支持越来越好了,php 4.3.x,'--enable-mbstring' '--with-iconv'后比较好的同时处理了UTF-8和其他中文字符集发布的RSS。
需要感谢Steve在PHP进行转码方面对MagPieRSS进行和XML Hacking工作。至少目前为止:Add to my yahoo还不能很好的处理utf-8字符集的RSS收藏。
记得年初Wen Xin在CNBlog的研讨会上介绍了个人门户的概念,随着RSS在CMS技术中的成熟,越来越多的服务可以让个人用户根据自己需求构建门户,也算是符合了互联网的非中心化趋势吧,比如利用Add to My Yahoo!功能,用户可以轻松的实现自己从更多数据源进行新闻订阅。想象一下把你自己的del.icio.us书签收藏 / flickr图片收藏 / Yahoo!新闻都通过这样一个RSS聚合器聚合/发布起来。其传播效率将有多快。
好比软件开发通过中间平台/虚拟机实现:一次写成,随处运行(Write once, run anywhere),通过RSS/XML这个中间层,信息发布也实现了:一次写成,随处发布(Write once, publish anywhere...)
安装Lilina需要PHP 4.3 以上,并带有iconv mbstring等函数的支持,请确认一下PHP模块的支持:'--enable-mbstring' '--with-iconv'
另外就是一个需要能通过服务器端向外部服务器发送RPC请求,这点51.NET不支持。感觉PowWeb的服务很不错,很多缺省的包都安装好了:
iconv
iconv support enabled
iconv implementation unknown
iconv library version unknown
Directive Local Value Master Value
iconv.input_encoding ISO-8859-1 ISO-8859-1
iconv.internal_encoding ISO-8859-1 ISO-8859-1
iconv.output_encoding ISO-8859-1 ISO-8859-1
mbstring
Multibyte Support enabled
Japanese support enabled
Simplified chinese support enabled
Traditional chinese support enabled
Korean support enabled
Russian support enabled
Multibyte (japanese) regex support enabled
将安装包解包(下载文件扩展名是.gz 其实是.tgz,需要重命名一下):上传到服务器相应目录下,注意:相应cache目录和当前目录的可写入属性设置,然后配置一下conf.php中的参数即可开始使用。
何东给我的建议:
1)右边的一栏,第一项的sources最好跟hobby、友情链接一样,加个图片。
2)一堆检索框在那儿,有些乱,建议只有一个,其它的放到一个二级页面上。
3)把联系方式及cc,分别做成一条或一个图片,放在右边一栏中,具体的内容可以放到二级页面上,因为我觉得好象没有多少人会细读这些文字。
4)如果可能,把lilina的头部链接汉化一下吧?
一些改进计划:
1 删除过长的摘要,可以通过寻找第2个"
" 实现;
2 分组功能:将RSS进行组输出;
修改默认显示实现:Lilina缺省显示最近1天发表的文章,如果需要改成其他时间周期可以找到:
$TIMERANGE = ( $_REQUEST['hours'] ? $_REQUEST['hours']*3600 : 3600*24 ) ;
进行改动。
RSS是一个能将自己的所有资源:WIKI / BLOG / 邮件聚合起来的轻量级协议,以后无论你在何处书写,只要有RSS接口就都可以通过一定方式进行再次的汇聚和发布起来,从而大大提高了个人知识管理和发布/传播效率。
以前对RSS理解非常浅:不就是一个DTD嘛,真了解起解析器来,才知道namespace的重要性,一个好的协议也应该是这样的:并非没有什么可加的,但肯定是没有什么可“减”的了,而真的要做到这个其实很难很难……。
我会再尝试一下JAVA的相关解析器,将其扩展到WebLucene项目中,更多Java相关Open Source RSS解析器资源。
另外找到的2个使用Perl进行RSS解析的包:
使用XML::RSS::Parser::Lite和XML::RSS::Parser 解析RSS
XML::RSS::Parser::Lite的代码样例如下:
#!/usr/bin/perl -w
# $Id$
# XML::RSS::Parser::Lite sample
use strict;
use XML::RSS::Parser::Lite;
use LWP::Simple;
my $xml = get("http://www.klogs.org/index.xml");
my $rp = new XML::RSS::Parser::Lite;
$rp->parse($xml);
# print blog header
print "<a href=\"".$rp->get('url')."\">" . $rp->get('title') . " - " . $rp->get('description') . "</a>\n";
# convert item to <li>
print "<ul>";
for (my $i = 0; $i < $rp->count(); $i++) {
my $it = $rp->get($i);
print "<li><a href=\"" . $it->get('url') . "\">" . $it->get('title') . "</a></li>\n";
}
print "</ul>";
安装:
需要SOAP-Lite
优点:
方法简单,支持远程抓取;
缺点:
只支持title, url, description这3个字段,不支持时间字段,
计划用于简单的抓取RSS同步服务设计:每个人都可以出版自己订阅的RSS。
XML::RSS::Parser代码样例如下:
#!/usr/bin/perl -w
# $Id$
# XML::RSS::Parser sample with Iconv charset convert
use strict;
use XML::RSS::Parser;
use Text::Iconv;
my $converter = Text::Iconv->new("utf-8", "gbk");
my $p = new XML::RSS::Parser;
my $feed = $p->parsefile('index.xml');
# output some values
my $title = XML::RSS::Parser->ns_qualify('title',$feed->rss_namespace_uri);
# may cause error this line: print $feed->channel->children($title)->value."\n";
print "item count: ".$feed->item_count()."\n\n";
foreach my $i ( $feed->items ) {
map { print $_->name.": ".$converter->convert($_->value)."\n" } $i->children;
print "\n";
}
优点:
能够直接将数据按字段输出,提供更底层的界面;
缺点:
不能直接解析远程RSS,需要下载后再解析;
2004-12-14:
从cnblog的Trackback中了解到了Planet RSS聚合器
Planet的安装:解包后,直接在目录下运行:python planet.py examples/config.ini 就可以在output目录中看到缺省样例FEED中的输出了index.html,另外还有opml.xml和rss.xml等输出(这点比较好)
我用几个RSS试了一下,UTF-8的没有问题,但是GBK的全部都乱码了,planetlib.py中和XML字符集处理的只有以下代码:看来所有的非UTF-8都被当作iso8859_1处理了:
try:
data = unicode(data, "utf8").encode("utf8")
logging.debug("Encoding: UTF-8")
except UnicodeError:
try:
data = unicode(data, "iso8859_1").encode("utf8")
logging.debug("Encoding: ISO-8859-1")
except UnicodeError:
data = unicode(data, "ascii", "replace").encode("utf8")
logging.warn("Feed wasn't in UTF-8 or ISO-8859-1, replaced " +
"all non-ASCII characters.")
近期学习一下Python的unicode处理,感觉是一个很简洁的语言,有比较好的try ... catch 机制和logging
关于MagPieRSS性能问题的疑虑:
对于Planet和MagPieRSS性能的主要差异在是缓存机制上,关于使用缓存机制加速WEB服务可以参考:可缓存的cms设计。
可以看到:Lilina的缓存机制是每次请求的时候遍历缓存目录下的RSS文件,如果缓存文件过期,还要动态向RSS数据源进行请求。因此不能支持后台太多的RSS订阅和前端大量的并发访问(会造成很多的I/O操作)。
Planet是一个后台脚本,通过脚本将订阅的RSS定期汇聚成一个文件输出成静态文件。
其实只要在MagPieRSS前端增加一个wget脚本定期将index.php的数据输出成index.html,然后要求每次访问先访问index.html缓存,这样不就和Planet的每小时生成index.html静态缓存一样了吗。
所以在不允许自己配置服务器脚本的虚拟主机来说Planet根本是无法运行的。
更多关于PHP中处理GBK的XML解析问题请参考:
MagPieRSS中UTF-8和GBK的RSS解析分析
2004-12-19
正如在SocialBrain 2005年的讨论会中,Isaac Mao所说:Blog is a 'Window', also could be a 'Bridge',Blog是个人/组织对外的“窗口”,而RSS更方便你将这些窗口组合起来,成为其间的“桥梁”,有了这样的中间发布层,Blog不仅从单点发布,更到P2P自助传播,越来越看到了RSS在网络传播上的重要性。
版权声明:可以转载,转载时请务必以超链接形式标明文章 Lilina:RSS聚合器构建个人门户(Write once, publish anywhere) 的原始出处和作者信息及本版权声明。
http://www.chedong.com/blog/archives/000646.html

Comments
请问如果更改默认显示7天的新闻,谢谢。
由: honren 发表于 2004年12月12日 晚上10时20分
我使用lilina已经一段时间了。
http://news.yanfeng.org
稍微改了一点UI。
如果你能改进它,那就好了。
由: mulberry 发表于 2004年12月13日 上午09时24分
老车同志,没觉得你使用lilina以来,主页的访问速度具慢吗?放弃吧,至少没必要当作首页,lilina还在技术还不成熟`~
由: kalen 发表于 2004年12月16日 上午10时33分
可以考虑一下用drupal
由: shunz 发表于 2004年12月28日 下午06时46分
可以试试我做的:http://blog.terac.com
每3小时抓取blog,然后每个选5条最新的,排序,聚合,生成静态xml,用xsl格式化显示。。。
由: andy 发表于 2005年01月06日 下午12时53分
车东同志,这样做不好:P
rss本来就在网上,你聚合它在你的网页上不仅损害了你自己主页的质量,而且迷惑了搜索引擎,造成你痛斥的“门户网站损害创作热情”的效果。还是不要聚合的好!
由: caomo 发表于 2005年01月15日 上午11时58分
我也使用lilina一段时间了,还用它给自己做了一个每日漫画的聚集,挺有意思的。
地址:http://www.cqcn.com/comics/index.php
由: eapass 发表于 2005年02月03日 下午01时48分
可以看看我用drupal的聚合功能做的中文BLOG集锦:
http://www.shunz.net/aggregator/categories/1
由: shunz 发表于 2005年02月03日 下午03时14分
请问车东大哥,如果服务器不支持iconv和mbstring,有什么方法可以解决出现的乱码吗?
回答: 没有其他办法……
由: 94smart 发表于 2005年02月18日 上午11时18分
你推荐的“Lilina”,应该怎么用啊,具体怎么操作了,才能使用它?麻烦相告,谢谢!!
由: lotus_cao 发表于 2005年04月01日 下午04时54分
为什么要把聚合界面定义成主页呢?
由: Zhang 发表于 2005年06月20日 晚上09时53分
看到不少人发表关于Google为什么不支持Rss的问题和看法,这个问题以前不止一个人问起过我,我坚持的看法是Google在有新的赢利基础替代搜索之前是不会支持Rss的,而且我也没有看出来Google需要支持Rss的必要。「虽然我会去Hack google的服务,使得自己有Rss可用」
因为Rss太简单了,简单到将搜索引擎的门坎到了一种令Google感觉到一种压力的地步。
利用rss,可以简单的绕过搜索引擎里面最复杂的一个环节:HTML parse的过程,而这个过程,是众多小型搜索引擎的门坎和瓶颈,因为Rss提供规整化的结构化的数据,使得搜索引擎数据整理的过程简单了许多。可以想象,如果Google支持Rss,那么等于将这个市场的门坎降低,会导致大量的小型的竞争对手来分享未被蚕食的long tail,Google还不至于傻到这个地步。
为什么MSN和Yahoo会支持Rss呢?
MSN和Yahoo的赢利空间里不像Google那么纯粹的倚赖搜索,例如MSN和Yahoo都是门户,服务是其核心,而不搜索。要击败Google这个巨人,可以有很多种做法,其中之一就是培养市场,让搜索市场的门坎降低,培养很多Google的潜在对手,最终使得这个行业的利润薄利化,达到消减Google的目的。
难道MSN和Yahoo不会被消减么?
当然会了,可是如果这样一个大的竞争对手(Google)不断壮大,有朝一日google进入服务(其实现在已经进入了网络服务行业)将反过来蚕食Yahoo和MSN的市场,那么还不如及早的阻击这个敌人。
ZT. by Roboo Meshfire 2005
由: Roboo Meshfire 儒豹 发表于 2005年07月22日 下午12时51分
车大哥
magpierss的地址错了,应该是
http://magpierss.sourceforge.net/
由: peter 发表于 2005年08月09日 上午10时25分
赞同这个观点:
rss本来就在网上,你聚合它在你的网页上不仅损害了你自己主页的质量,而且迷惑了搜索引擎,造成你痛斥的“门户网站损害创作热情”的效果。还是不要聚合的好!
我看这个 在线RSS聚合器 很新鲜的: 独逸网RSS聚合: http://www.duyee.cn
由: rock 发表于 2005年10月12日 夜间03时23分
有一个很奇怪的问题,不知道大家注意到没有,还是只在我这里才出现. 我现在在添加"搜狐图吧",当然添加的过程是很顺利的,但是当我打开lilina试图浏览内容时,发现图片都没有显示出来. 不大清楚是怎么回事.
希望有人能帮我解决!
由: James 发表于 2005年12月30日 下午12时30分
Rss problem: many feeds from several sites are the same (duplicate), and the users see many duplicate content!
由: Roboo儒豹手机搜索引擎 发表于 2006年04月30日 下午02时29分