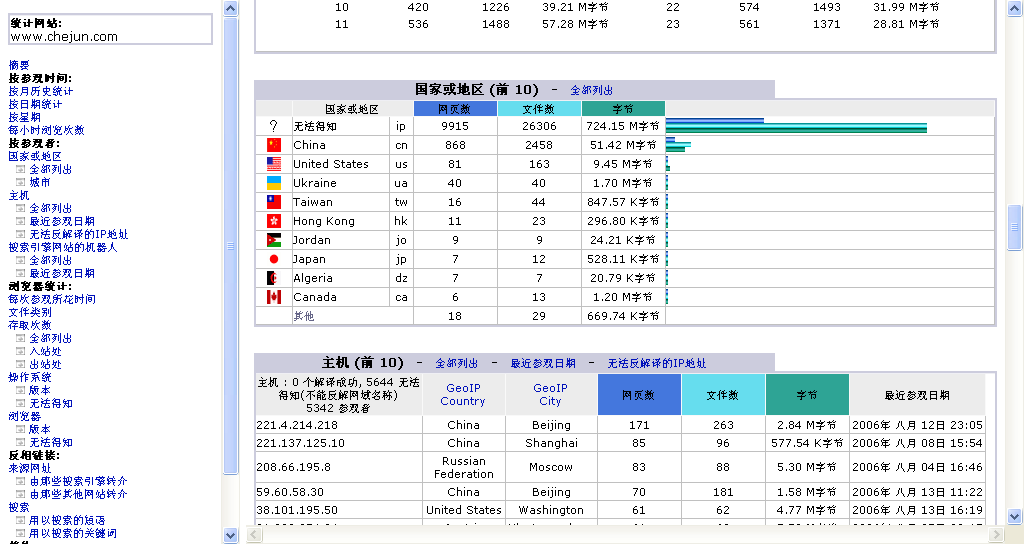
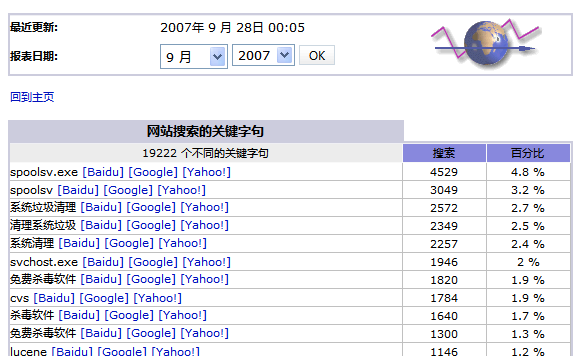
从上7月开始:我发现自己的AWStats统计中出现了gb2312和sitehao123这个关键词而且量很大:
gb2312 6515 11.3 %
spoolsv 3152 5.5 %
spoolsv.exe 2712 4.7 %
cvs 1873 3.2 %
apache 1761 3 %
phpinfo 1600 2.7 %
lucene 1160 2 %
sitehao123 1157 2 %
ant 864 1.5 %
但无论从那个搜索引擎上搜,通过这2个关键词也找不到我的页面啊?检查了一下统计,gb2312从6月份的统计中就开始有了。8月1日,新的一轮AWStats统计开始,仔细检查了一下apache的原始日志:从来源看,应该是来自百度的搜索结果页:
"http://www.baidu.com/s?lm=0&si=&rn=10&tn=sitehao123&ie=gb2312&ct=0&wd=免费杀毒软件&pn=10&cl=3"
其中tn是百度的合作网站代码,ie表示input encoding:表示输入字符串的字符集,而AWStats中有一个选项:
LevelForKeywordsDetection=2 # 0 disables Keyphrases/Keywords detection.
当设置为2的时候,会将来源网址中的所有参数进行遍历和自动识别,容易将一些其他参数的值当成关键词参数,这样的统计结果会丢失来源中实际的关键词。
解决方法:
除了修改awstats.pl代码外,awstats其实在search_engines.pm中有一个参数列表定义:专门用于过滤掉可能产生歧义的参数列表:WordsToCleanSearchUrl
@WordsToCleanSearchUrl= ('act=','annuaire=','btng=','cat=','categoria=','cfg=','cof=','cou=','count=','cp=','dd=','domain=','dt=','dw=','enc=','exec=','geo=','hc=','height=','hits=','hl=','hq=','hs=','id=','kl=','lang=','loc=','lr=','matchmode=','medor=','message=','meta=','mode=','order=','page=','par=','pays=','pg=','pos=','prg=','qc=','refer=','sa=','safe=','sc=','sort=','src=','start=','style=','stype=','sum=','tag=','temp=','theme=','type=','url=','user=','width=','what=','\\.x=','\\.y=','y=','look=');
将tn=和ie=加入到其中:tn=','ie=','
以后输出的参数中就不会有gb2312和tn=的值了。